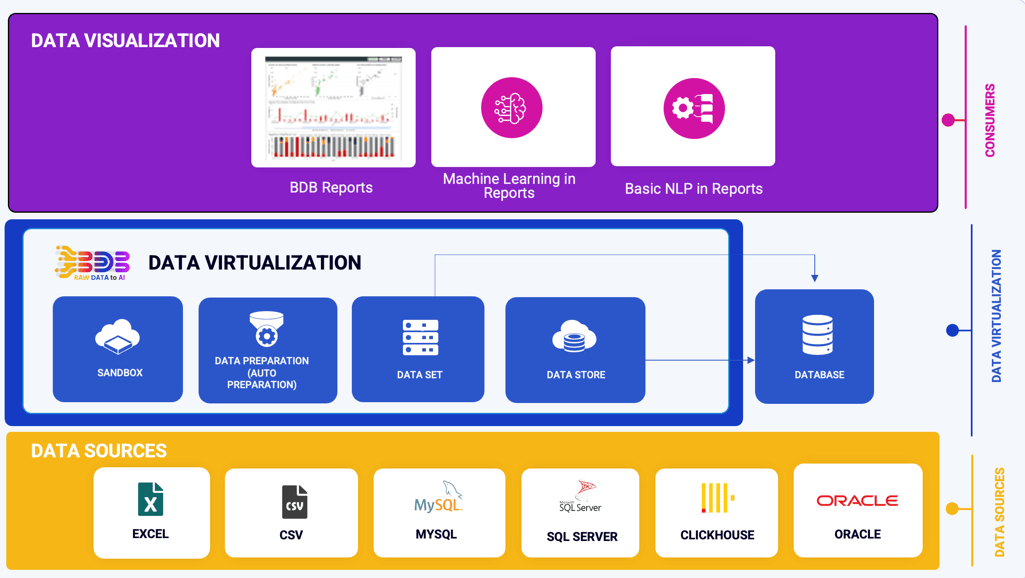
To seamlessly integrate your desktop and local data into the BDB platform, leverage the Sandbox or choose from the array of connectors available within the platform. Employ the Data Preparation tools to efficiently clean and refine your data. Establish a robust Data Store, often referred to as the BDB Cube, to organize and optimize your data for analysis. Within a matter of minutes, visualize your refined data using the platform's intuitive features.
Data Visualization Segment

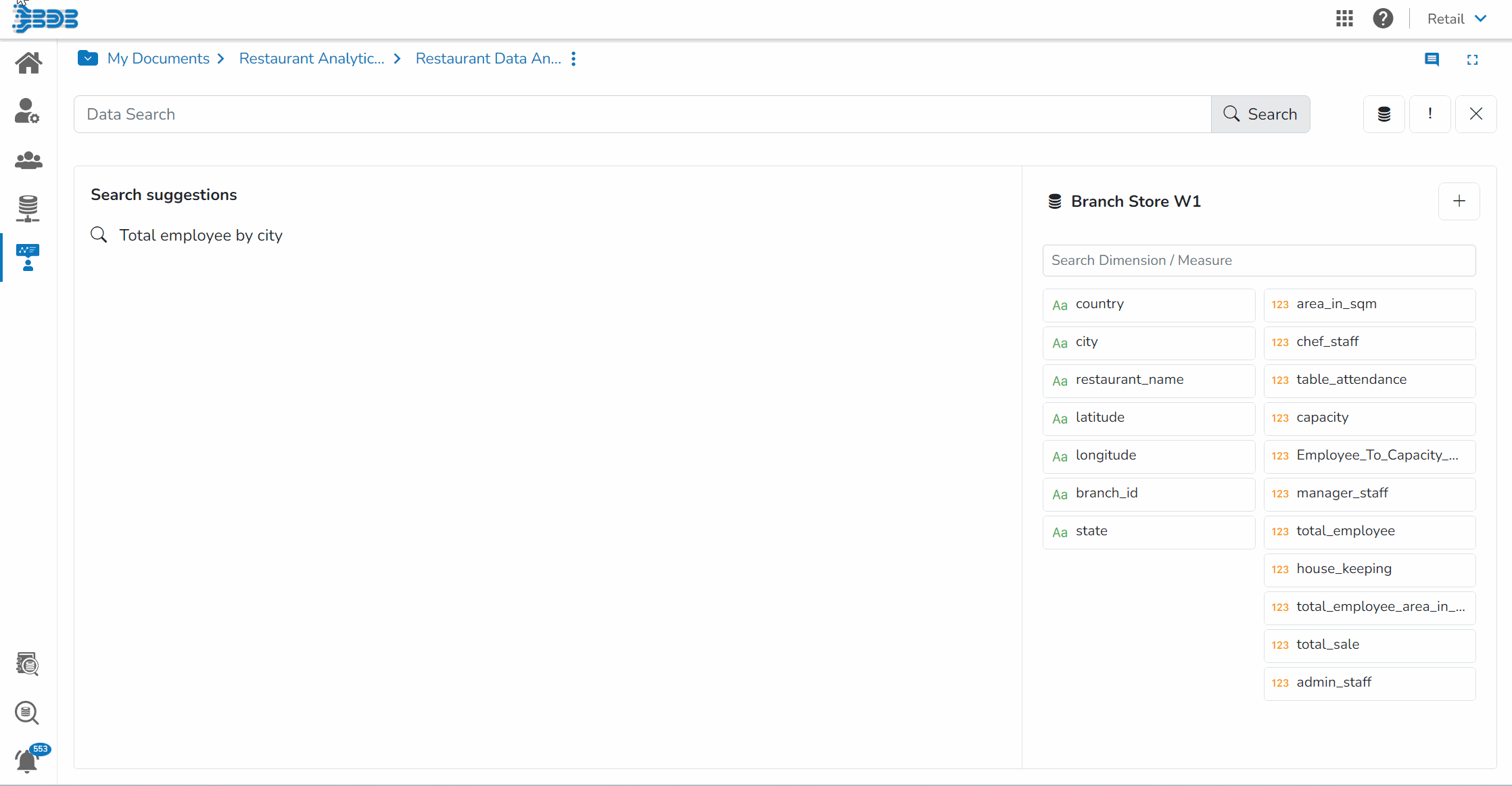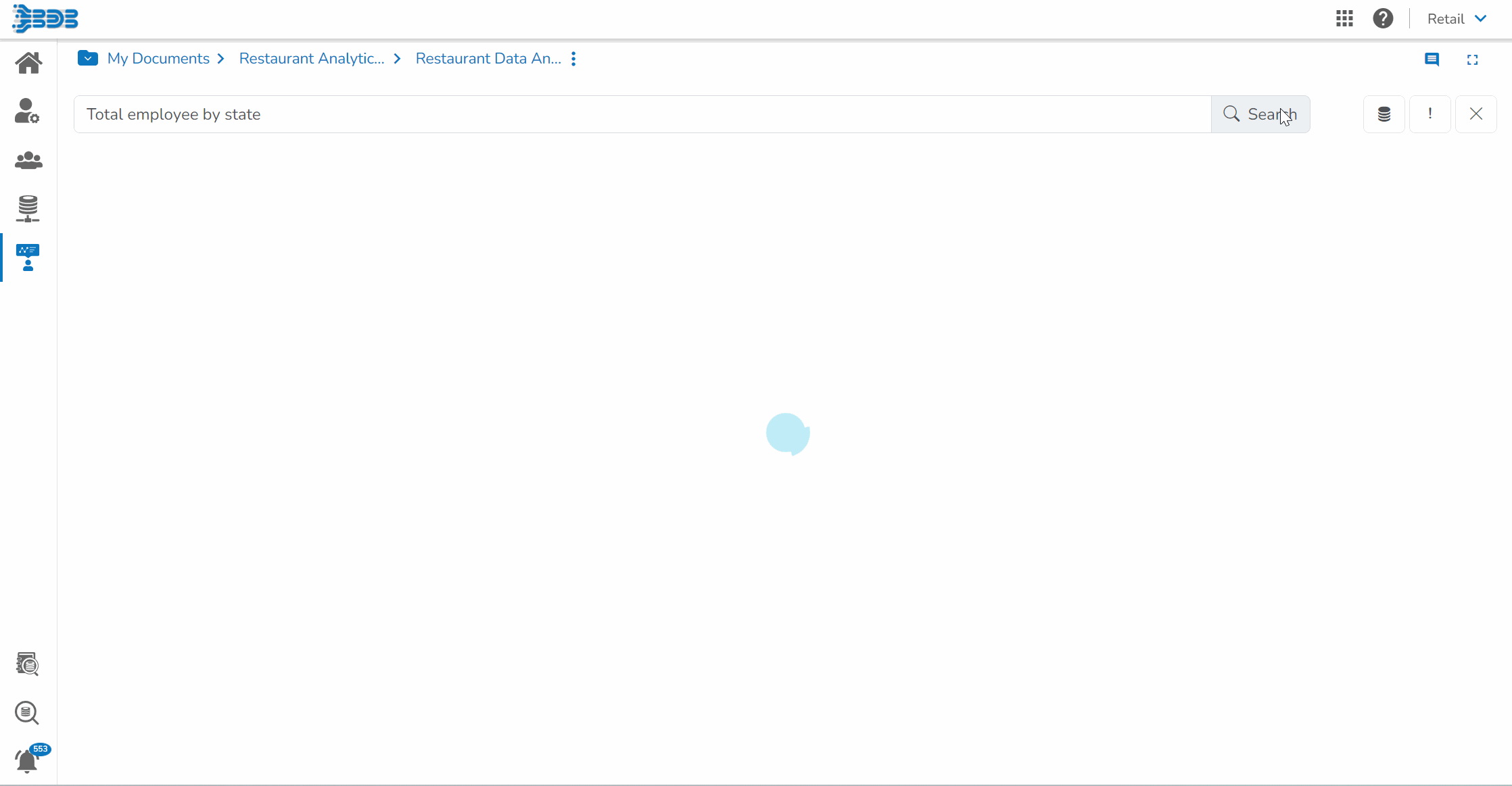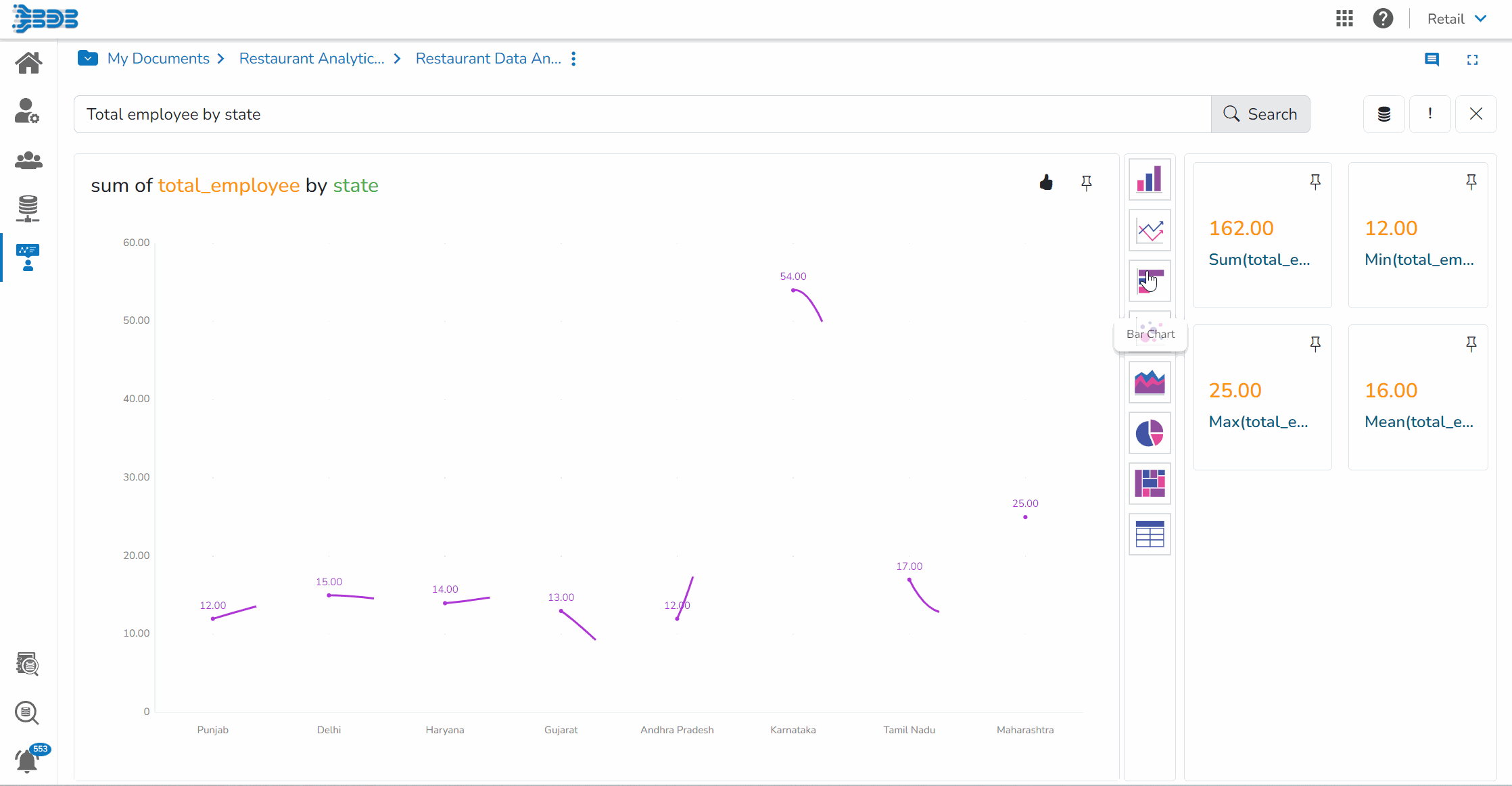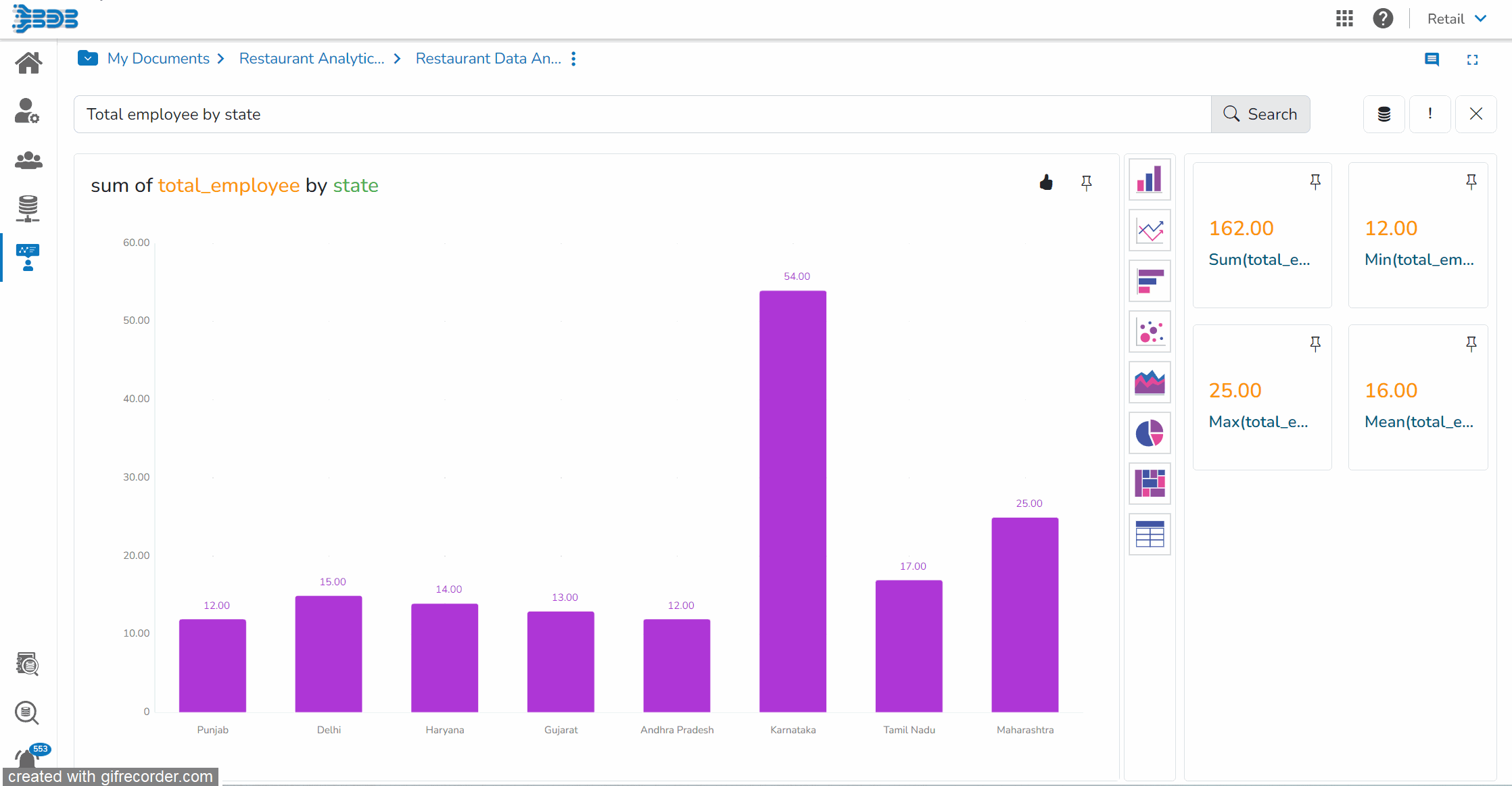
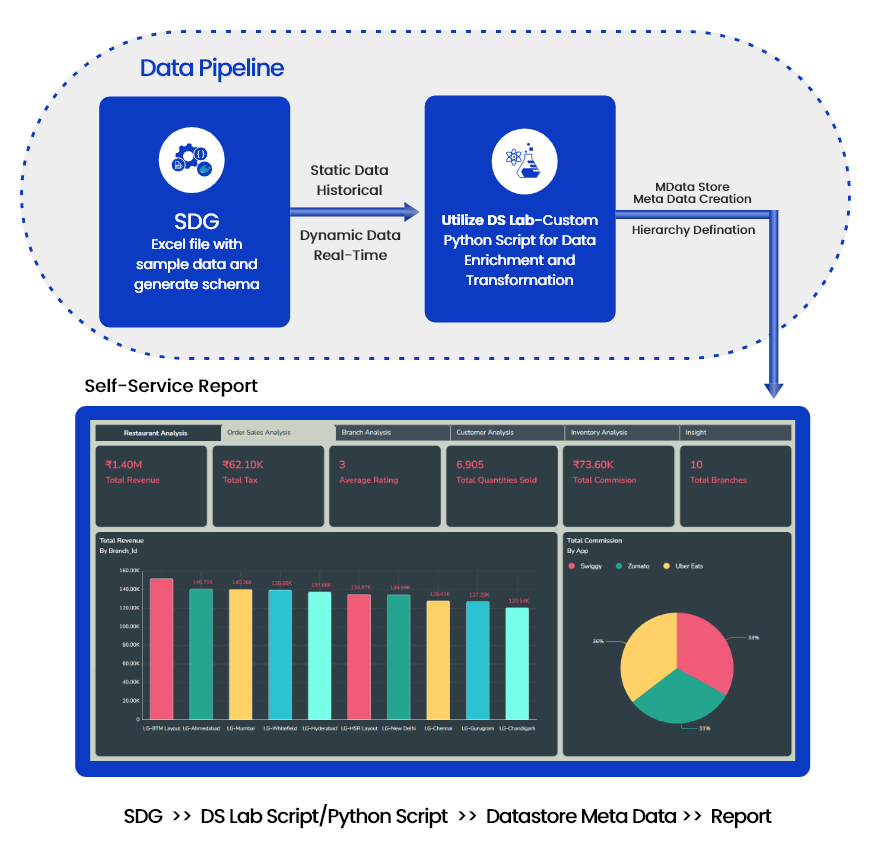
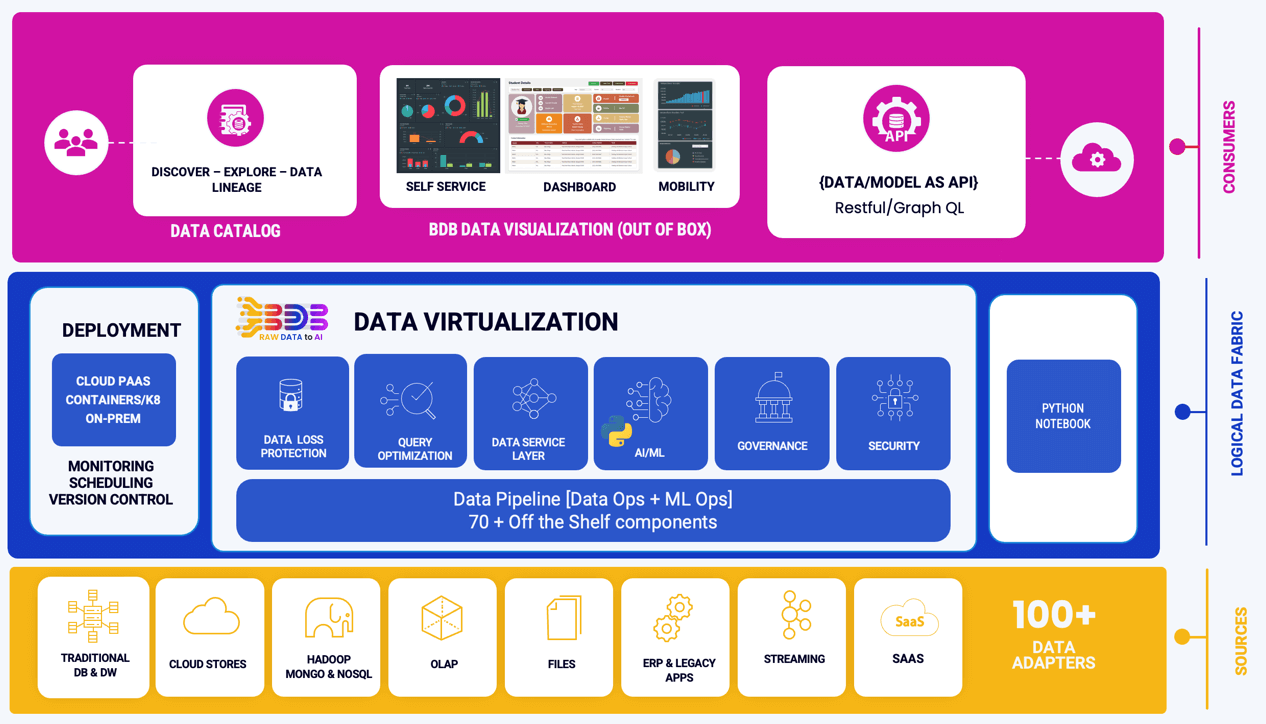
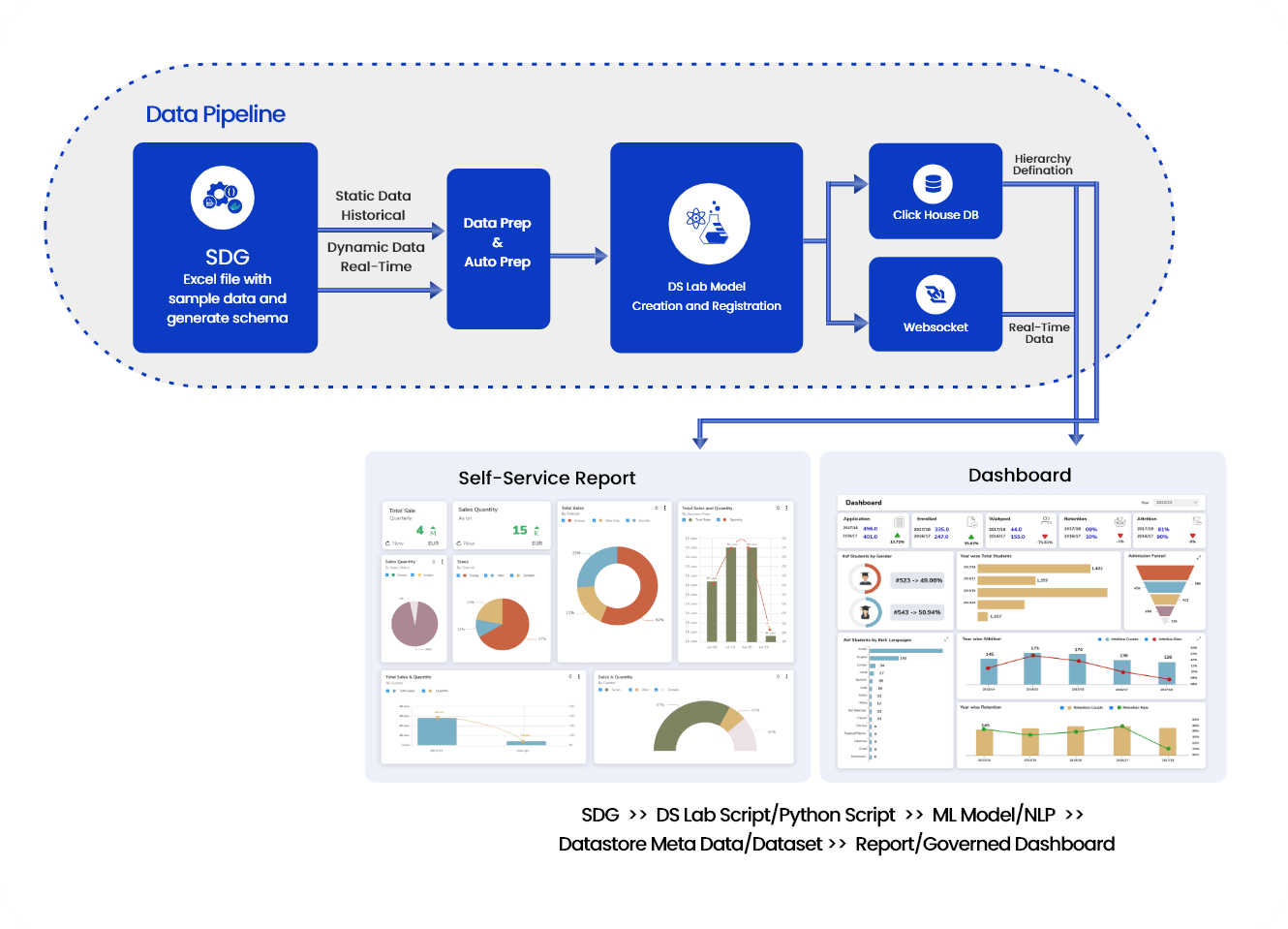
Ingest data (real time, Batch, Micro batch) from your multiple sources of data, enrich it, transform it (via Python code or Data Preparation tool of BDB), push this data into any data lake of your choice or BDB Data stores and Visualise the data in Self Service Reports or Governed Dashboards.
Documentation Page
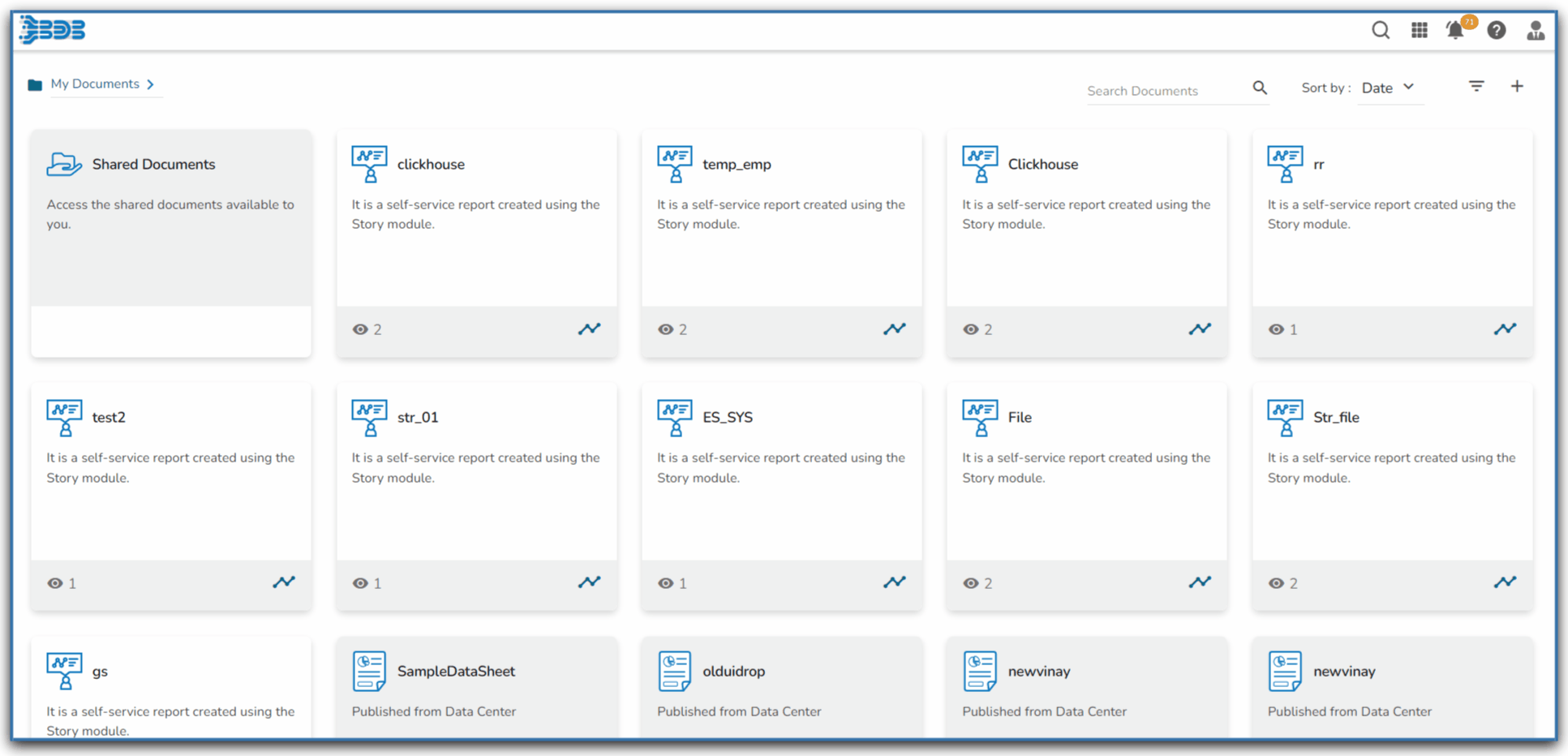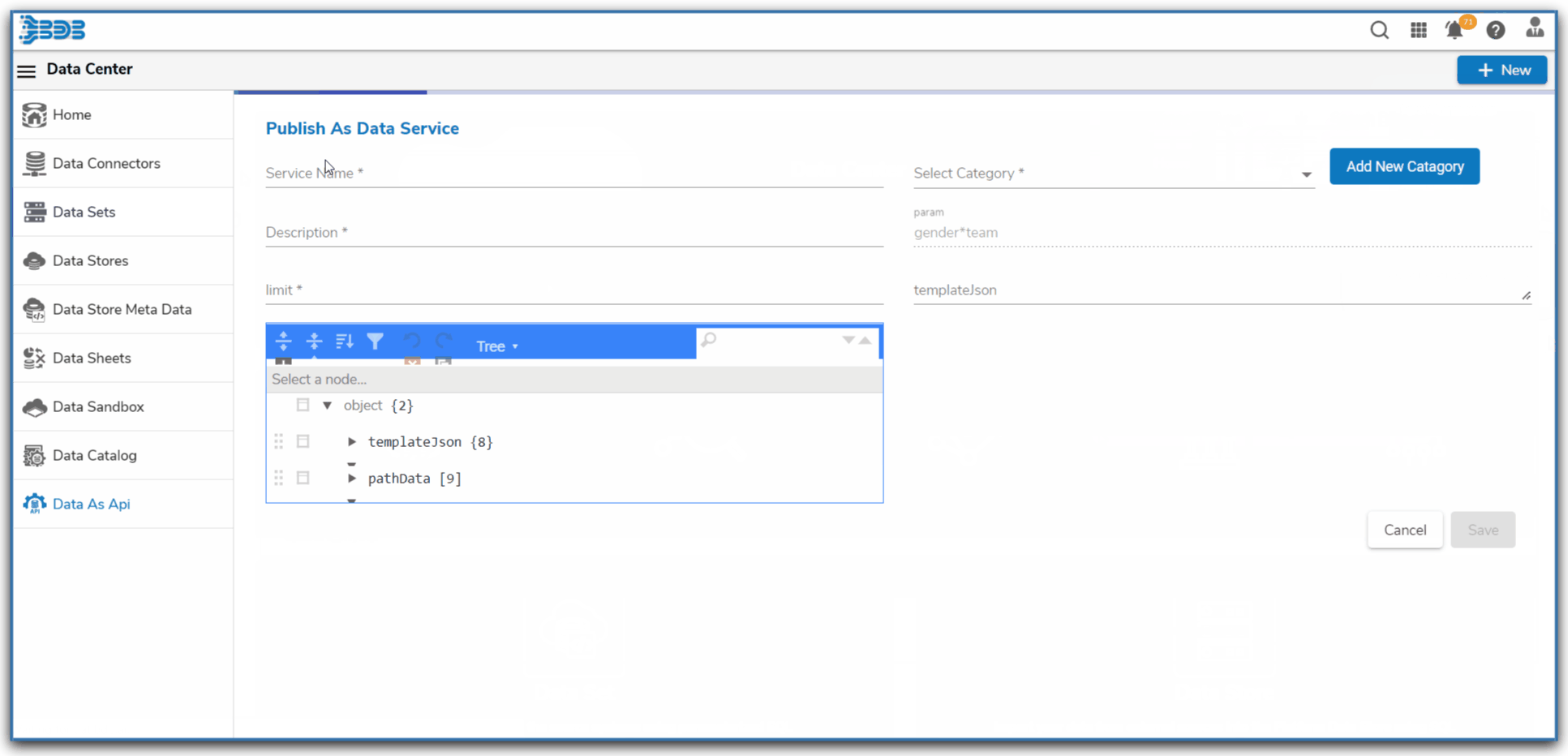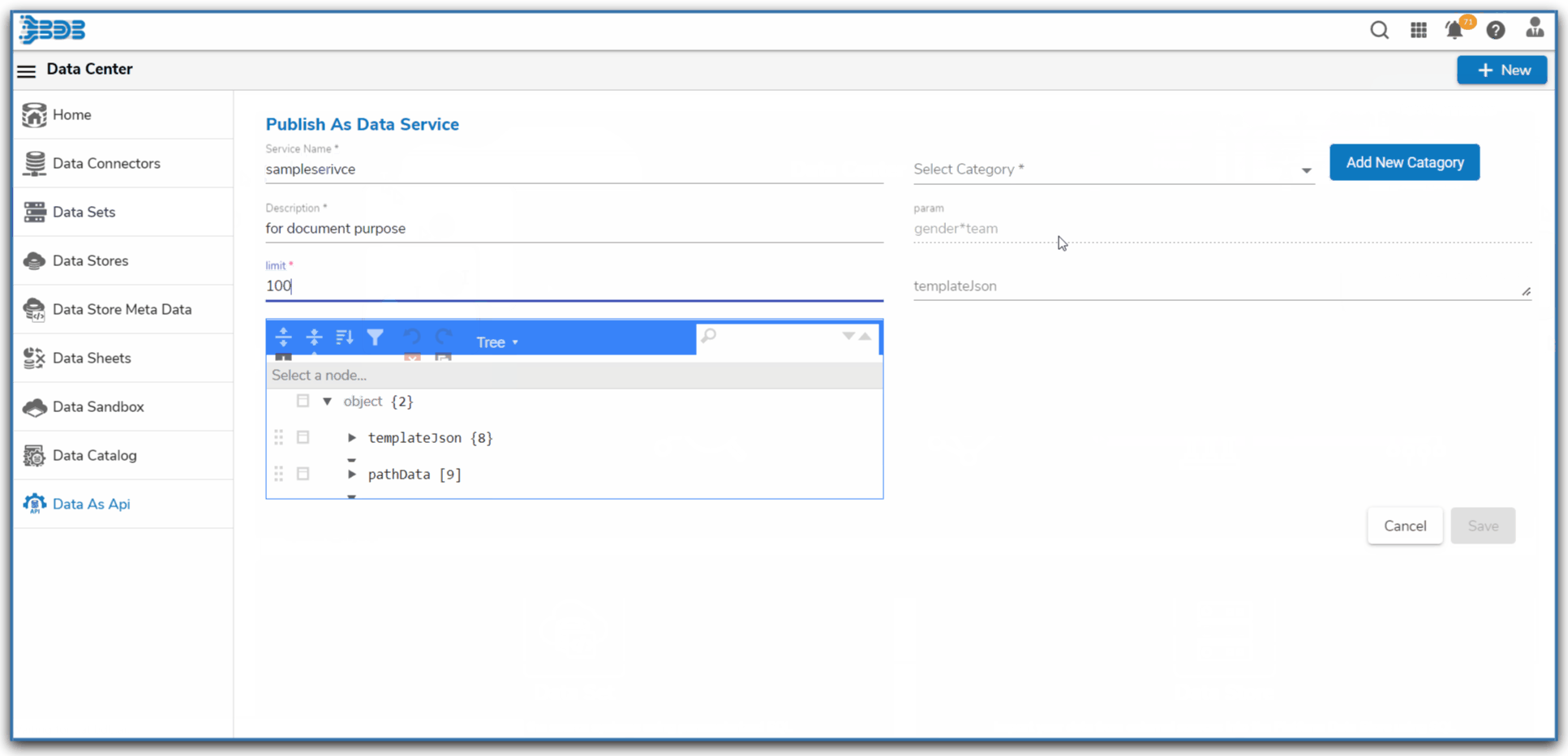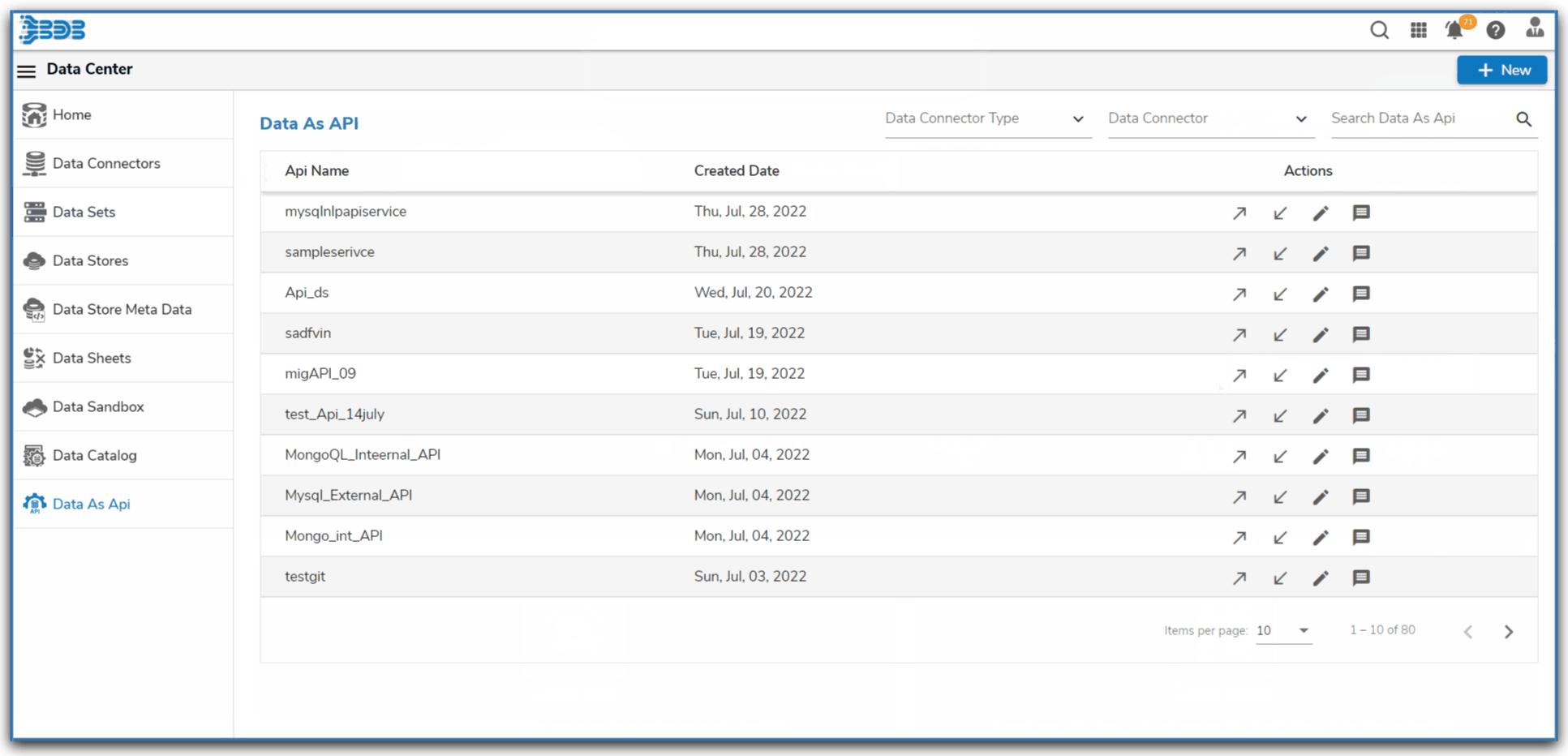

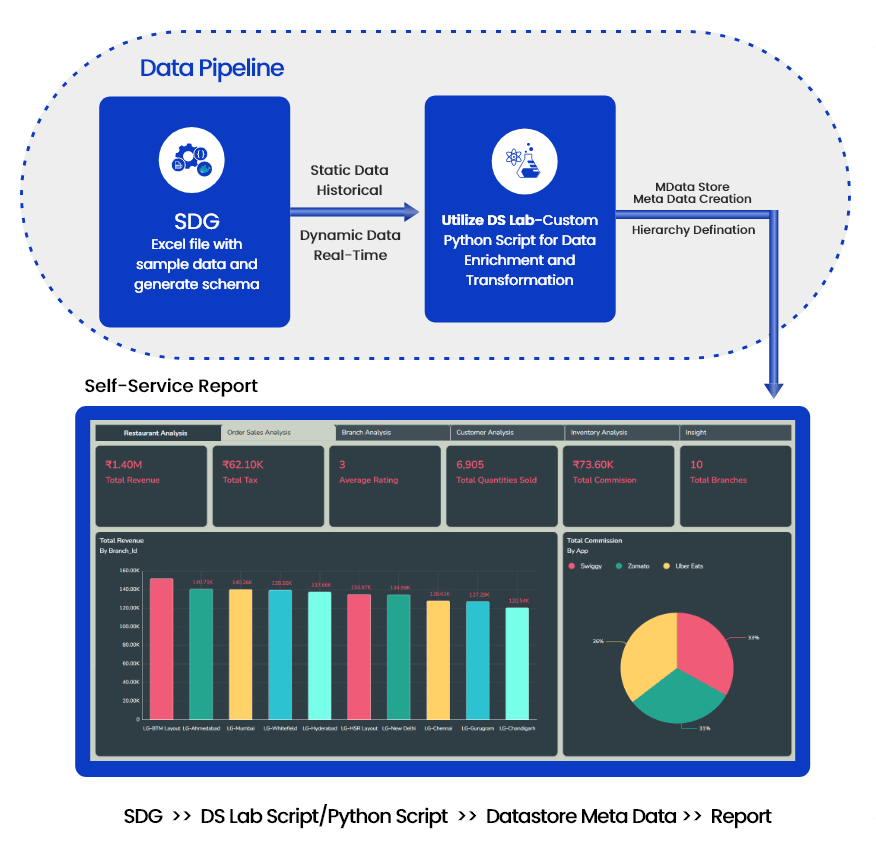
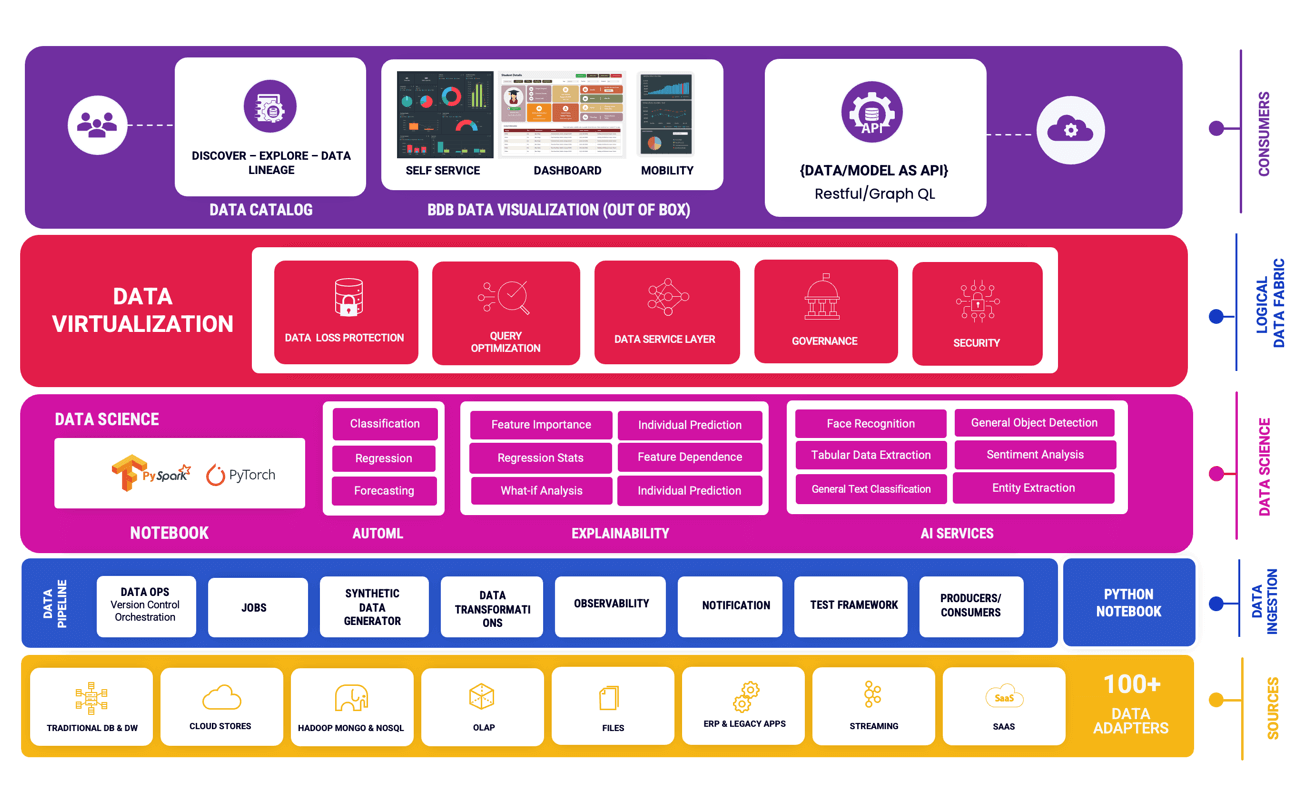
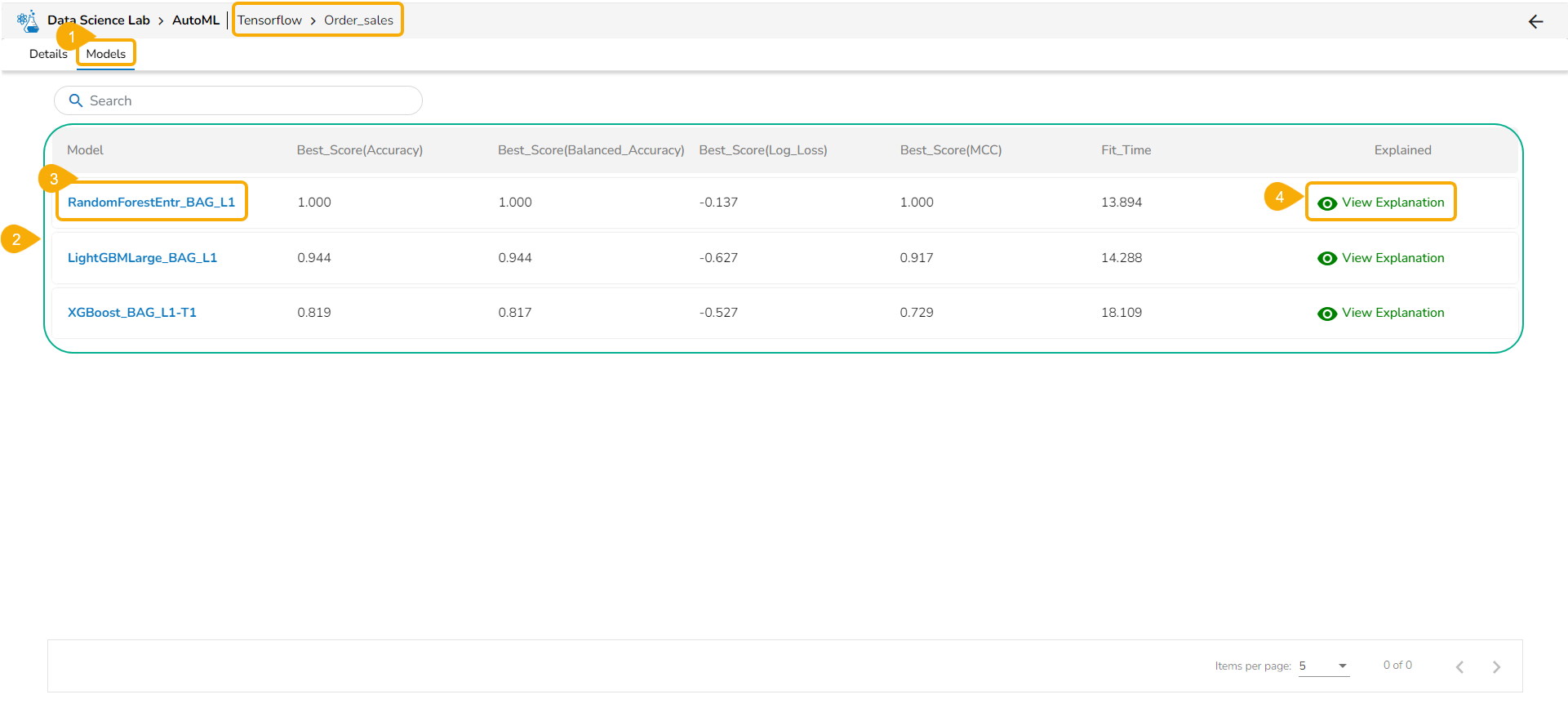
Ingest data (real time, Batch, Micro batch) from your multiple sources of data, enrich it, transform it (via Python code or Data Preparation tool of BDB), pass it through Multiple Models & push this data into any data lake of your choice or BDB Data stores and Visualise the data in Self Service Reports or Governed Dashboards. One can use Auto ML or library of Algorithms to build and deploy their models quickly in the platform.
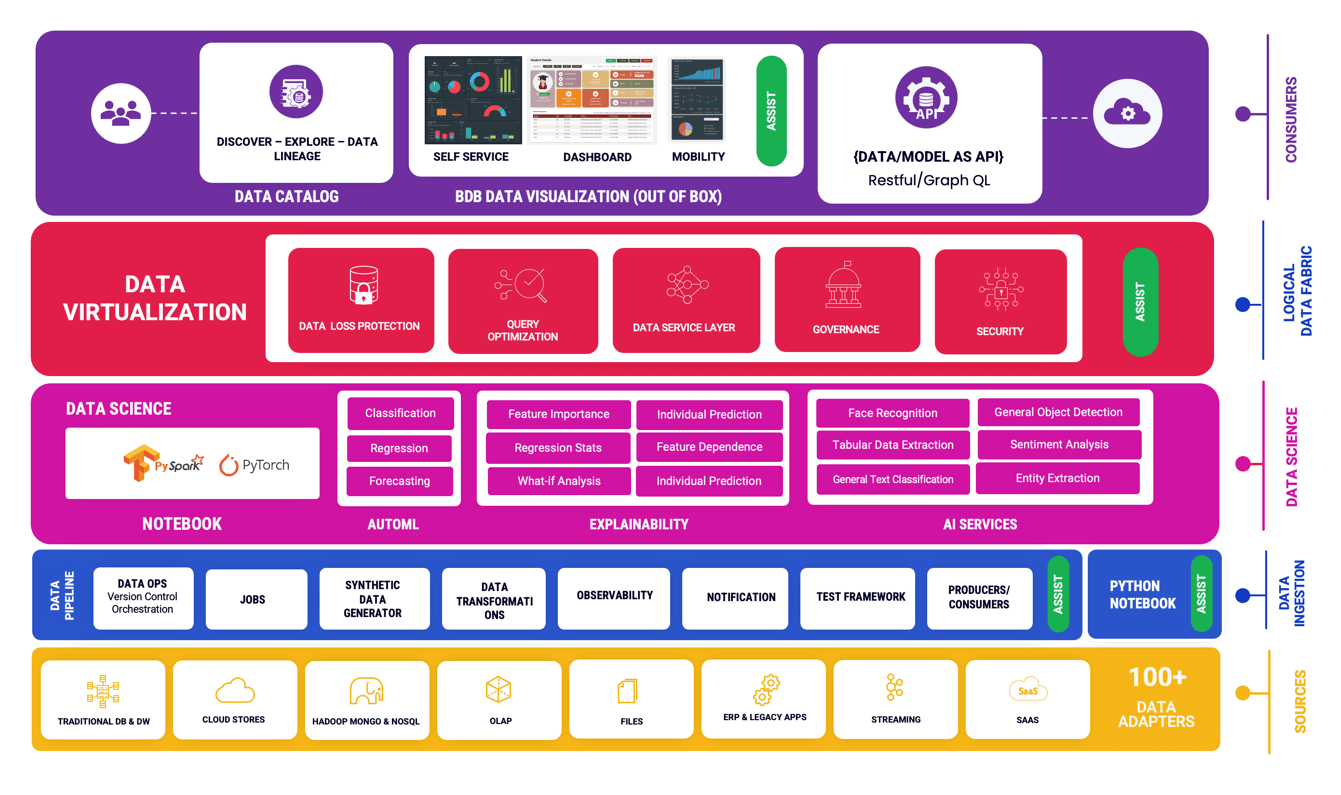
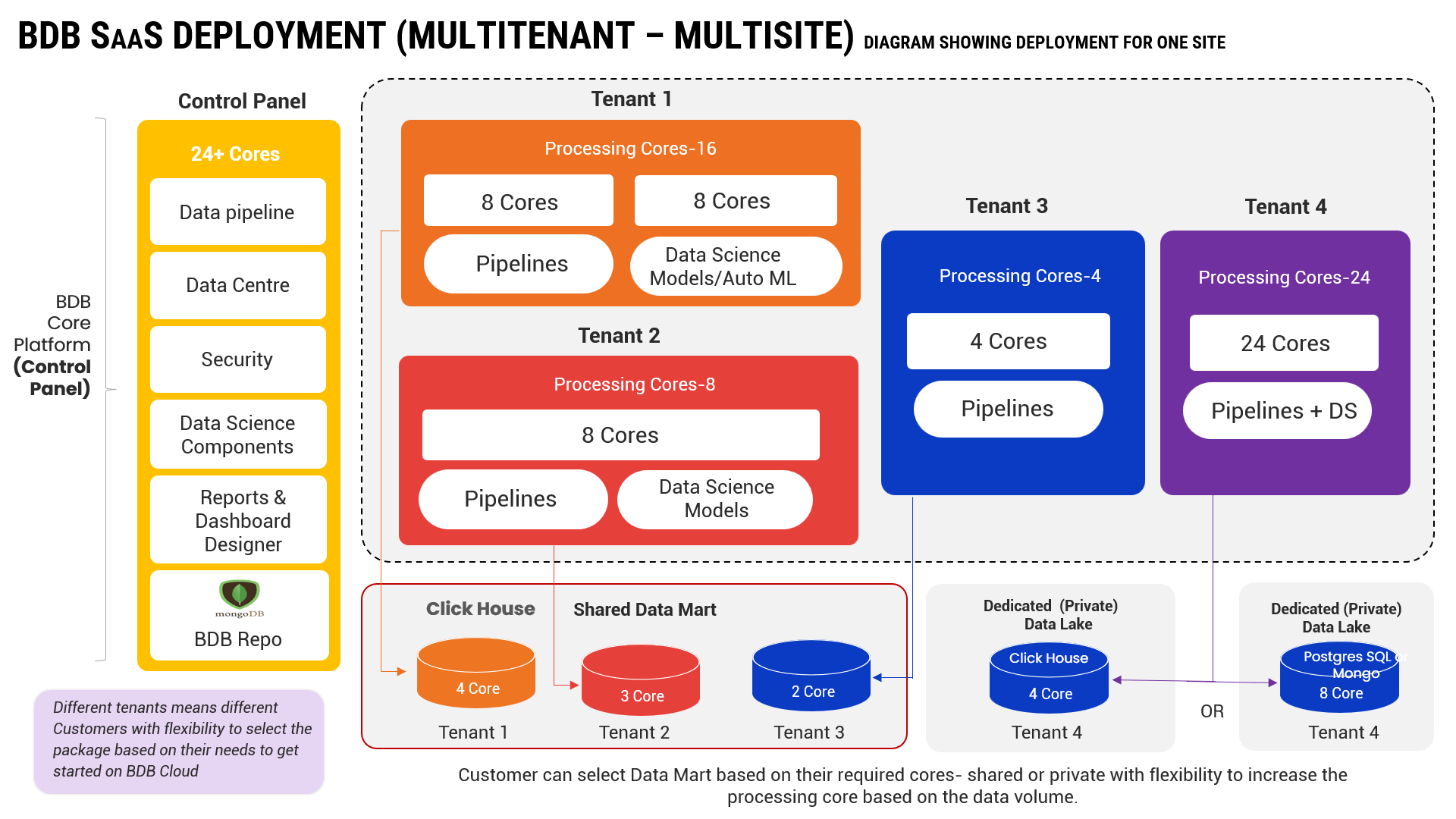
Assist has been developed and given inside BDB platform to help developers create contents in a fast manner. This package has End to End Platform features (Data Science Package) therefore it allocates higher no of Cores already.