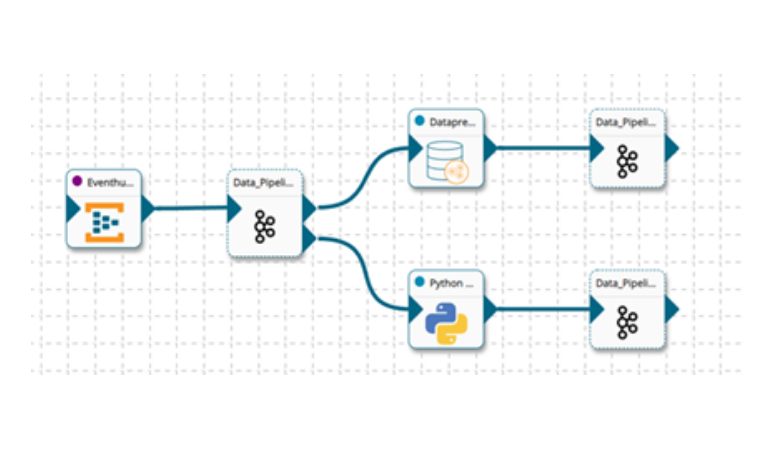
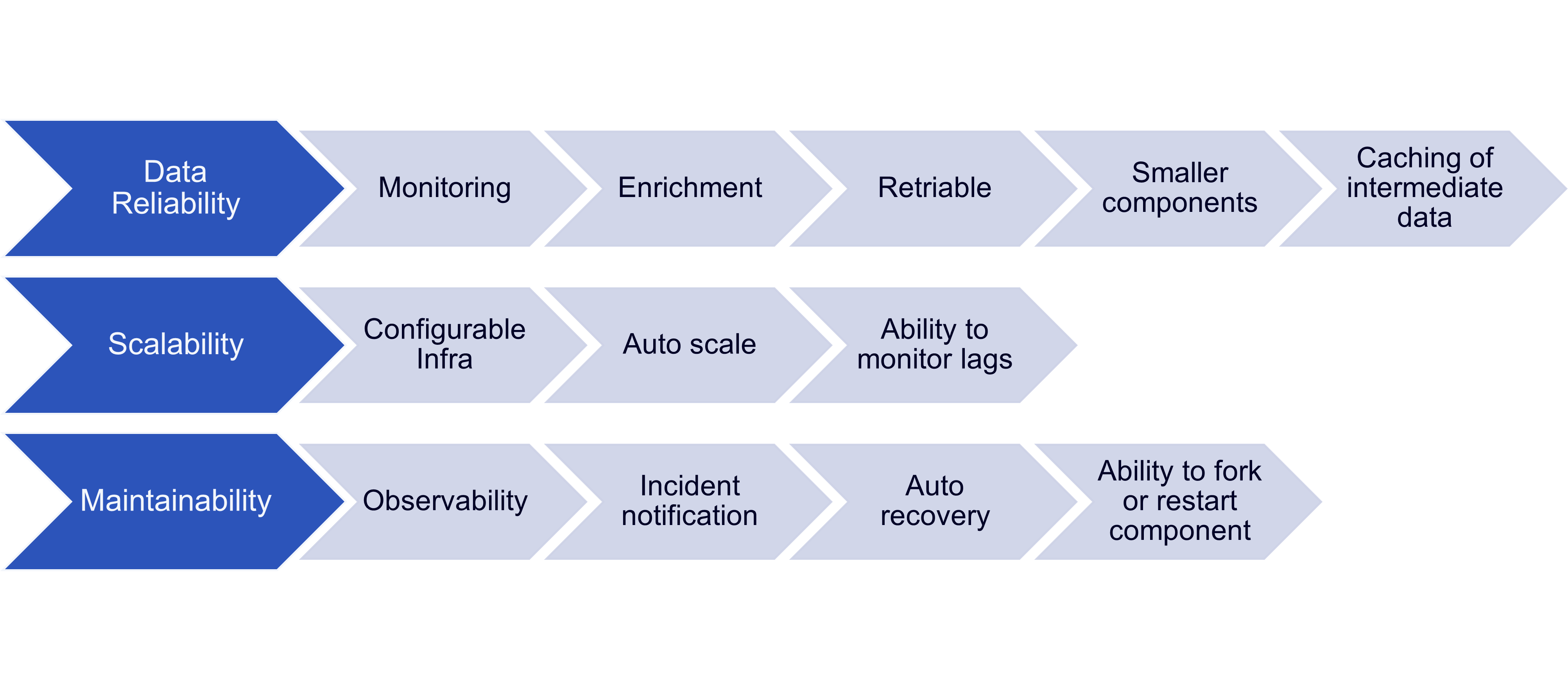
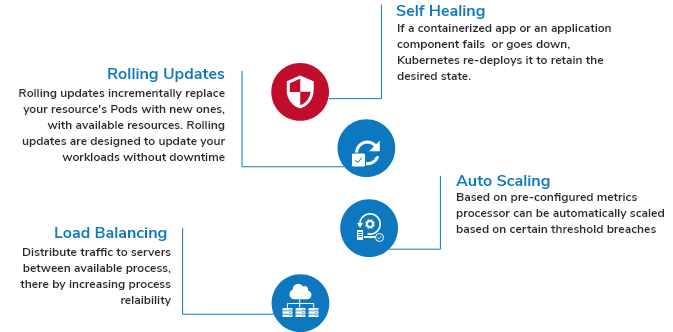
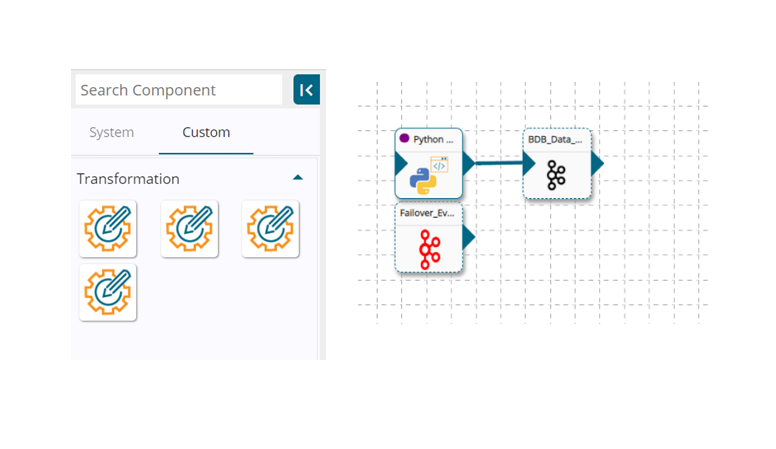
Pre-Build Components
-

Azure
-

Azure Cosmosdb Reader
-

Azure Docker
-

Azure Reader Metadata
-

Cassandra
-

Clickhouse Producer
-

ES
-

GCS Monitor
-

HDFS
-

JDBC
-

MongoDB Reader Python
-

MongoDB Reader
-

Notification Subscriber
-

S3 Reader
-

Sandbox Reader
-

SFTP
-

SFTP Excel Reader
-

Azure Cosmosdb Writer
-

Azure Writer
-

Cassandra Writer
-

Clickhouse Writer
-

ES Writer
-

HDFS Writer
-

JDBC Writer
-

MongoDB Writer Python
-

MongoDB Writer
-

S3 Writer
-

Sandbox Writer
-

Video Writer
-

API Server Ingestion
-

AWS SNS
-

Event Hub
-

GCS Monitor
-

Kafka Consumer
-

MongoDB Change Stream
-

Mqtt Consumer
-

OPC UA
-

Rabbitmq Consumer
-

SFTP Monitoring
-

Sqoop
-

Twitter Scrapper
-

Video Stream Consumer
-

Data Generator
-

Event Grid
-

Event Hub
-

Kafka Producer
-

Notification Publisher
-

Rabbitmq Producer
-

Websocket Producer
-

ETL
-

Data Preparation
-

DLP
-

Email Component
-

Enrichment Component
-

File Splitter
-

Flatter Json
-

MongoDB Aggregation
-

Pandas
-

Query
-

Rest Api
-

Rule Splitter
-

Schema Validator
-

Stored Procedure Runner
-

Custom Pytyhon Scripting
-

Custom Script
-

Schedulers
-

Auto ML
-

Notebook
-
Azure
-
Azure Cosmosdb Reader
-
Azure Docker
-
Azure Reader Metadata
-
Cassandra
-
Clickhouse Producer
-
ES
-
GCS Monitor
-
HDFS
-
JDBC
-
MongoDB Reader Python
-
MongoDB Reader
-
Notification Subscriber
-

S3 Reader
-
Sandbox Reader
-
SFTP
-
SFTP Excel Reader
-
Azure Cosmosdb Writer
-
Azure Writer
-
Cassandra Writer
-
Clickhouse Writer
-
ES Writer
-
HDFS Writer
-
JDBC Writer
-
MongoDB Writer Python
-
MongoDB Writer
-
S3 Writer
-
Sandbox Writer
-
Video Writer
-
Data Generator
-
Event Grid
-
Event Hub
-
Kafka Producer
-
Notification Publisher
-
Rabbitmq Producer
-
Websocket Producer
-
ETL
-
Data Preparation
-
DLP
-
Email Component
-
Enrichment Component
-
File Splitter
-
Flatter Json
-
MongoDB Aggregation
-
Pandas
-
Query
-
Rest Api
-
Rule Splitter
-
Schema Validator
-
Stored Procedure Runner
-
API Server Ingestion
-
AWS SNS
-
Event Hub
-
GCS Monitor
-
Kafka Consumer
-
MongoDB Change Stream
-
Mqtt Consumer
-
OPC UA
-
Rabbitmq Consumer
-
SFTP Monitoring
-
Sqoop
-
Twitter Scrapper
-
Video Stream Consumer
-
Custom Pytyhon Scripting
-
Custom Script
-
Schedulers
-
Auto ML
-
Notebook