Your AI Agent Just Made Up Your Revenue Number. Here Is Why — and How to Fix It Permanently.
Picture this scenario. You have just deployed an AI agent to answer business questions from your data. Your CFO asks it: "What was our net revenue last quarter?" The agent returns a number. Confidently. Instantly. It looks right. It is wrong.
Not because the AI model is bad. Not because your data warehouse has missing records. But because the phrase "net revenue" means three different things in three different systems — and the AI agent, querying raw tables, had no way of knowing which definition to apply. So it guessed. And it presented that guess in the same authoritative tone it uses for everything else.
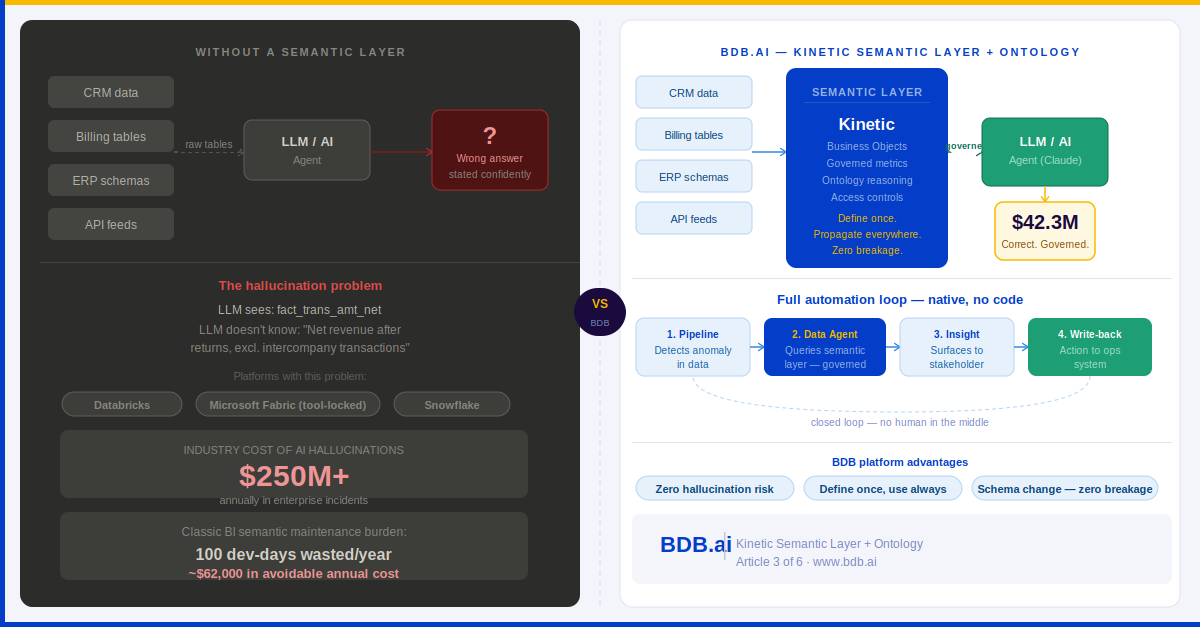
This is not a hypothetical. It is the most common failure mode in enterprise AI deployments in 2025. Industry research indicates that hallucination-related incidents now cost enterprises more than $250 million annually — and the majority of those incidents are not caused by a broken model. They are caused by an AI querying data that has no governed business meaning attached to it.
The root cause is an architecture problem. And it has a name: the absence of a Semantic Layer.
Before we discuss the solution, it is worth understanding why this problem is so widespread. The three platforms most commonly deployed in enterprise analytics today each handle — or more precisely, fail to handle — semantic governance in a structurally different way.
Databricks: No Semantic Layer, by Design
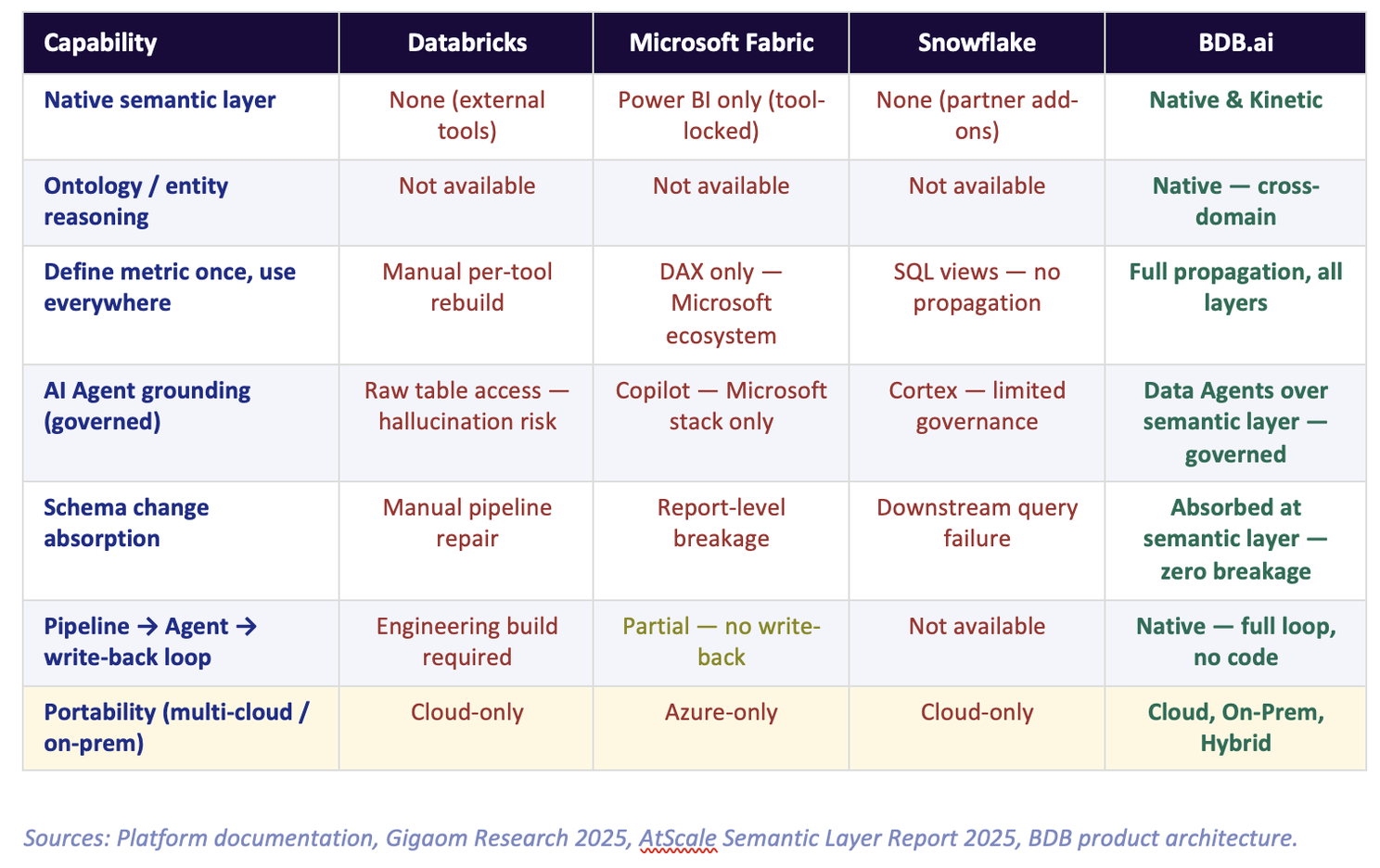
Databricks was built for data engineers, not for business users. Its architecture is centred on the Lakehouse — exceptional for large-scale transformation and ML. But there is no native semantic layer. When you wire an LLM or a Data Agent to Databricks, it queries raw Delta Lake tables. It sees column names like fact_trans_amt_net and dim_cust_seg_cd. It has no idea that these map to "Net Revenue after returns, excluding intercompany" and "Customer Segment as defined by the Marketing taxonomy." Every AI interaction on an ungoverned Databricks environment is a hallucination waiting to happen.
The workaround — dbt semantic models, third-party tools like Cube or AtScale — adds cost, complexity, and a new integration layer to maintain. The problem is not solved. It is deferred.
Microsoft Fabric / Power BI: Semantics Locked Inside the Tool
Microsoft's approach is more sophisticated — Power BI has a genuine semantic model built on DAX. But it is architecturally imprisoned. The semantic definitions live inside .pbix files and Fabric datasets, optimised specifically for Microsoft's VertiPaq in-memory engine. If your organisation uses Tableau for one team, Qlik for another, or a Python-based ML pipeline for a third — none of them can access the Power BI semantic model. Each tool must rebuild its own definitions from scratch.
The result is what the industry now calls semantic sprawl: the same metric defined differently in five tools, reconciled manually in quarterly meetings, and completely invisible to any AI agent that operates outside the Microsoft ecosystem.
Snowflake: No Semantic Layer, Partner Dependency
Snowflake is a world-class data storage and compute engine. It is not a semantic platform. There is no native semantic layer — Snowflake's answer is a partner ecosystem: AtScale, Looker, Tableau, or Cube on top. Each of these is a separate license, a separate implementation, and a separate maintenance burden. Snowflake Cortex (its AI layer) operates on raw tables with limited governance. The semantic problem is fully outsourced.
Here is where all three platforms stand on the capabilities that matter most for AI-driven automation:
What BDB's Kinetic Semantic Layer Actually Does Differently
BDB's Semantic Layer is not a bolt-on. It is the architectural spine of the entire platform — the single metadata layer through which every component operates: pipelines, dashboards, ML models, Data Agents, self-service reports, and mobile interfaces.
The word "Kinetic" is deliberate. Unlike static semantic models that require manual versioning and synchronisation, BDB's layer propagates changes dynamically across all consumers the moment a definition is updated. There is no reconciliation step. There is no "publish and notify." There is no team of developers updating 200 reports after a source system change.
But the deeper differentiation is the Ontology layer — a capability that does not exist in any of the three platforms above.
The Ontology: Where Business Meaning Becomes Machine-Readable Reasoning
A semantic layer defines metrics and dimensions. An ontology defines relationships — between business concepts, between entities, between domains.
In BDB, the Ontology maps:
-
How entities relate across domains — Customer links to Order links to Product links to Supplier. A query about "customers at risk" traverses this graph automatically, not through hand-written SQL joins.
-
How business concepts are consistently represented — once data has been ingested and consolidated from multiple sources, the Ontology ensures every downstream query, dashboard, and AI Agent applies the same canonical definition, eliminating the drift that accumulates when each tool defines its own version.
-
What a concept means in vertical context — "Churn" in telecom is different from "Churn" in retail is different from "Churn" in banking. The Ontology encodes these domain-specific definitions so that AI Agents apply the right logic for the right industry without prompt engineering.
This is the architectural reason BDB Data Agents — integrated natively with Claude, OpenAI or any other LLM — do not hallucinate on business questions. They never see raw tables. They operate entirely over governed Semantic Objects: named, versioned, tested business concepts that carry their own definitions, relationships, and access controls.
An LLM querying raw tables is guessing at business meaning. An LLM querying a governed ontology is reasoning with it. The outputs look similar. The reliability is not.
Define Once. Propagate Everywhere. Automatically.
In a classic BI environment, business logic lives inside the tools that consume it. Every dashboard, every ML model, every scheduled report carries its own copy of the calculation for "Monthly Active Users" or "Gross Margin by Channel." When the definition changes — and it always changes — a developer must hunt down every affected object and update it manually.
In a large enterprise, this is not a minor inconvenience. It is a structural source of data inconsistency, and it gets worse with every new tool added to the stack.
BDB's Semantic Layer inverts this architecture. Business logic lives in the semantic layer, not inside the consumers. When "Gross Margin" is redefined — say, to exclude a newly acquired subsidiary — the change is made once, in one place. Every dashboard, every AI Agent query, every ML feature that references Gross Margin inherits the update automatically. No developer intervention. No risk of one report showing the old number while another shows the new one.
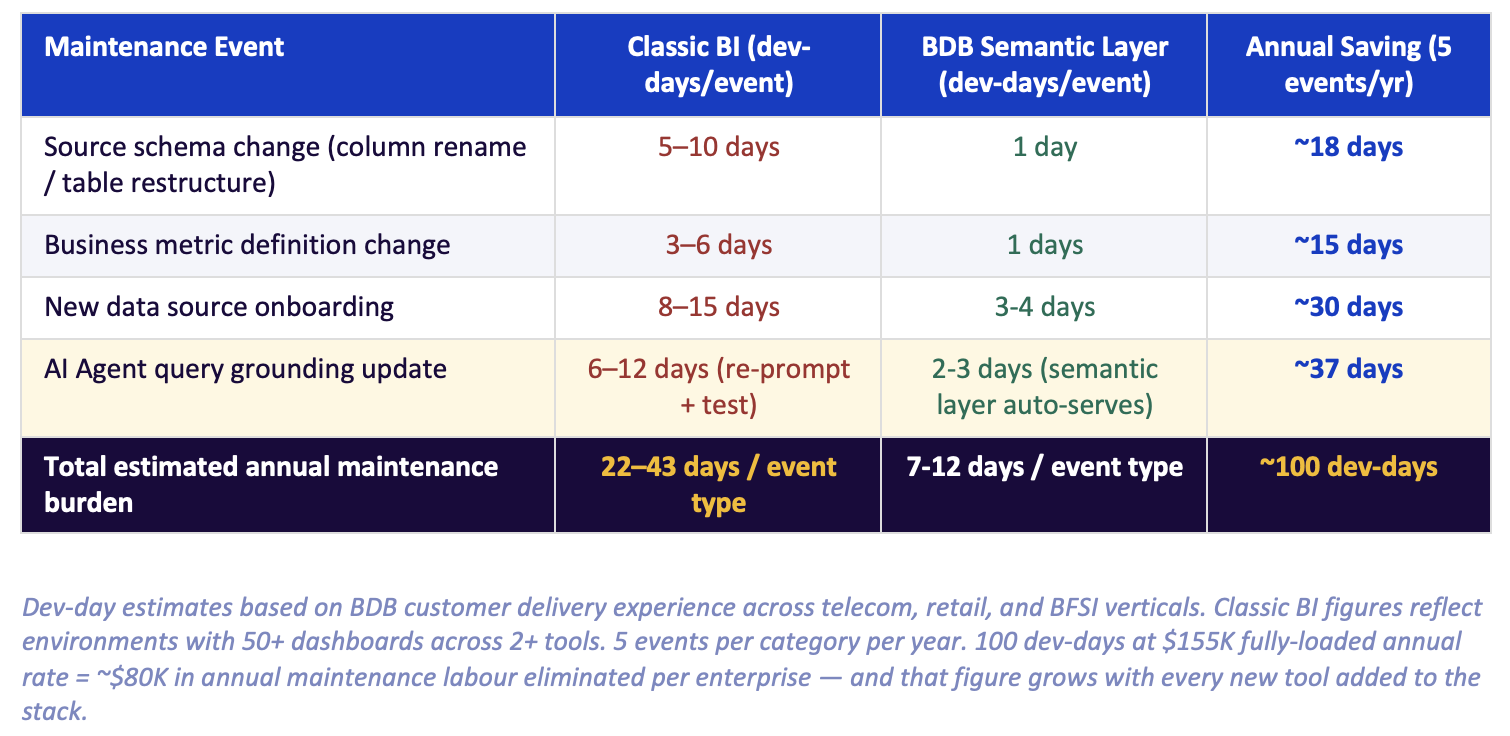
In five years of managing a classic BI environment with quarterly source system changes, the average enterprise spends more on semantic maintenance than on the platform license itself. BDB eliminates that cost category.
Here is what that maintenance burden looks like in practice — and what BDB's architecture removes:
The Full Loop: Pipeline to Agent to Write-Back
The highest-value automation use case in enterprise analytics is not a dashboard. It is a closed loop: a system that detects a condition in data, reasons about it, surfaces an insight, and triggers an action — without a human in the middle of every step.
Classic BI platforms cannot close this loop. They stop at visualisation. A human reads the dashboard, decides what to do, and acts manually. The platform's job ends when the chart renders.
BDB's architecture closes the loop natively because every component shares the same semantic foundation:
1
Detection: A BDB Pipeline detects an anomaly in incoming data — say, a sudden drop in transaction volume for a retail region. The semantic layer already knows what "normal" looks like for this metric in this context.
2
Reasoning: A BDB Data Agent is triggered. It queries governed Semantic Objects — not raw tables — to understand the root cause. It traverses the Ontology to check whether the anomaly correlates with inventory levels, regional promotions, or competitor pricing data.
3
Surfacing: The Agent surfaces a structured insight to the relevant business stakeholder — a regional manager, a supply chain lead — through a governed dashboard alert or a mobile notification. The insight includes the reasoning chain, not just the number.
4
Action: With BDB's write-back capability, the Agent can push a recommendation directly to an operational system — a promotion trigger, a restocking order, a risk flag in the CRM — completing the loop without manual intervention.
This is what "agentic AI" actually looks like in production. Not a chatbot answering questions. A system that acts on governed data through a semantic foundation that makes every step of the automation reliable.
None of the three platforms compared above can deliver this loop natively. Databricks can approximate steps one and two with significant engineering effort. Microsoft Fabric can surface an insight within the Power BI ecosystem. Neither can close to step four without a custom build on top.
The semantic layer is not a BI convenience. It is the infrastructure that determines whether your AI agents can be trusted — and whether your automation can reach production without an engineer reviewing every output.
What to Ask Your Current Platform Vendor
If you are evaluating or renewing a data platform contract, here are four questions that will reveal whether their semantic architecture can support the AI automation roadmap you are planning:
-
Where does your business logic live? If the answer is "inside Power BI" or "in our dbt models," ask what happens when you add a second BI tool or a third AI agent. The answer will tell you whether you have a semantic layer or a collection of semantic islands.
-
What happens to our dashboards and AI queries when a source schema changes? If the answer involves "developer effort to update affected reports," you do not have a propagating semantic layer. You have a manual maintenance obligation.
-
Can our AI agents query governed business definitions — or do they query raw tables? If the answer is raw tables, your AI outputs carry hallucination risk on every business query that involves a non-trivial metric definition.
-
Does your platform support write-back — can an AI agent close the loop into an operational system? If the answer is no, your automation ceiling is a dashboard.
We are happy to walk through how BDB's Semantic Layer and Ontology are configured for specific verticals — telecom, retail, BFSI, healthcare, education — and show exactly how a Data Agent grounded in governed semantics performs against one querying raw tables. The difference is not subtle.
Next in this series: Article 4 examines why "deployment flexibility" is the most undervalued capability in enterprise platform selection — and what it actually costs when your platform cannot follow your data to where it needs to live.
Read more about Your AI Agent Just Made Up Your Revenue Number