Content Assist Flow
In today's fast-paced digital age, efficient information retrieval is crucial for businesses and individuals alike. The ability to quickly access relevant information can significantly impact decision-making processes. With the advent of advanced technologies, solutions are constantly evolving to enhance the way we retrieve and utilise knowledge. One such innovative approach is Retrieval Augment Generation, facilitated by the powerful BDB platform. In this article, we will explore the steps involved in leveraging BDB Platform
Step 1: Converting Documents/Knowledge Base to Embeddings
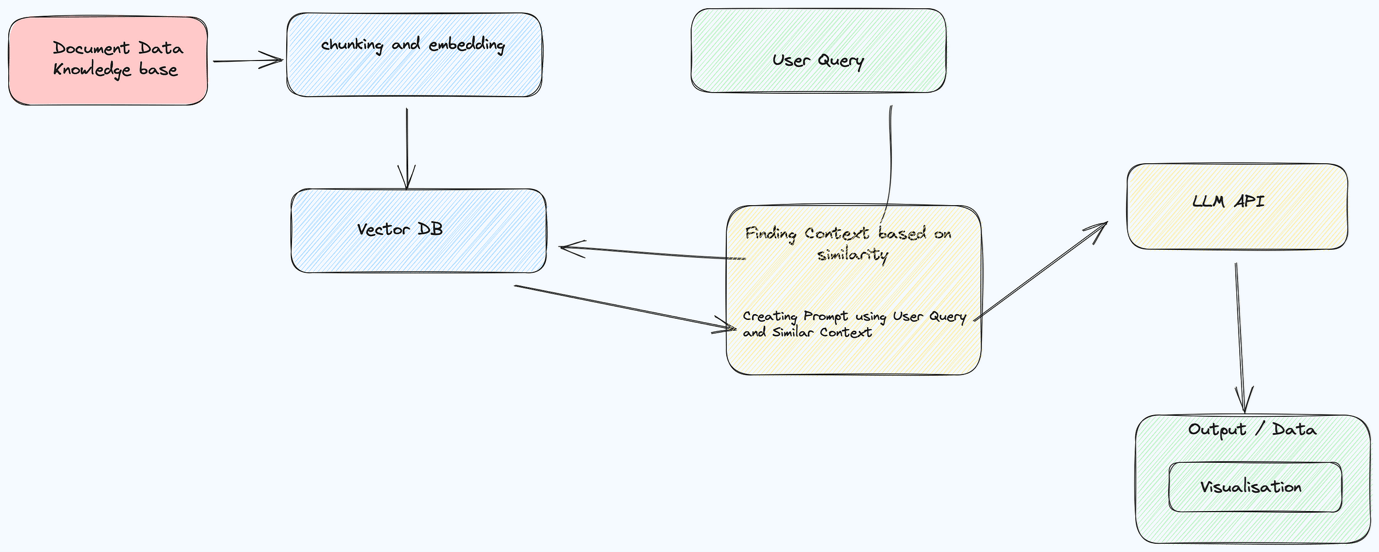
BDB Pipeline for creating & storing documents Embeddings
The journey of retrieval augment generation begins by transforming textual data into a format that can be easily processed and analyzed.
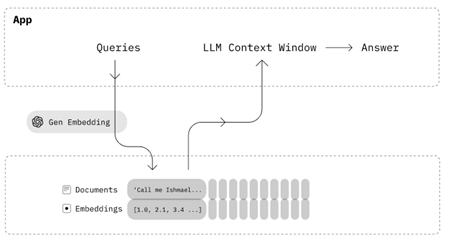
Open Source embeddings or OpenAI embeddings play a pivotal role in this step. These embeddings are essentially numerical representations of words or documents, capturing their semantic meanings. By converting documents or a knowledge base into embeddings, information is transformed into a format that can be efficiently stored and manipulated.
These embeddings are then stored in a Vector Database (Vector DB), a high-performance database optimized for handling vector data. Vector DB allows for quick retrieval and similarity searches, ensuring that the converted information is readily accessible when needed.
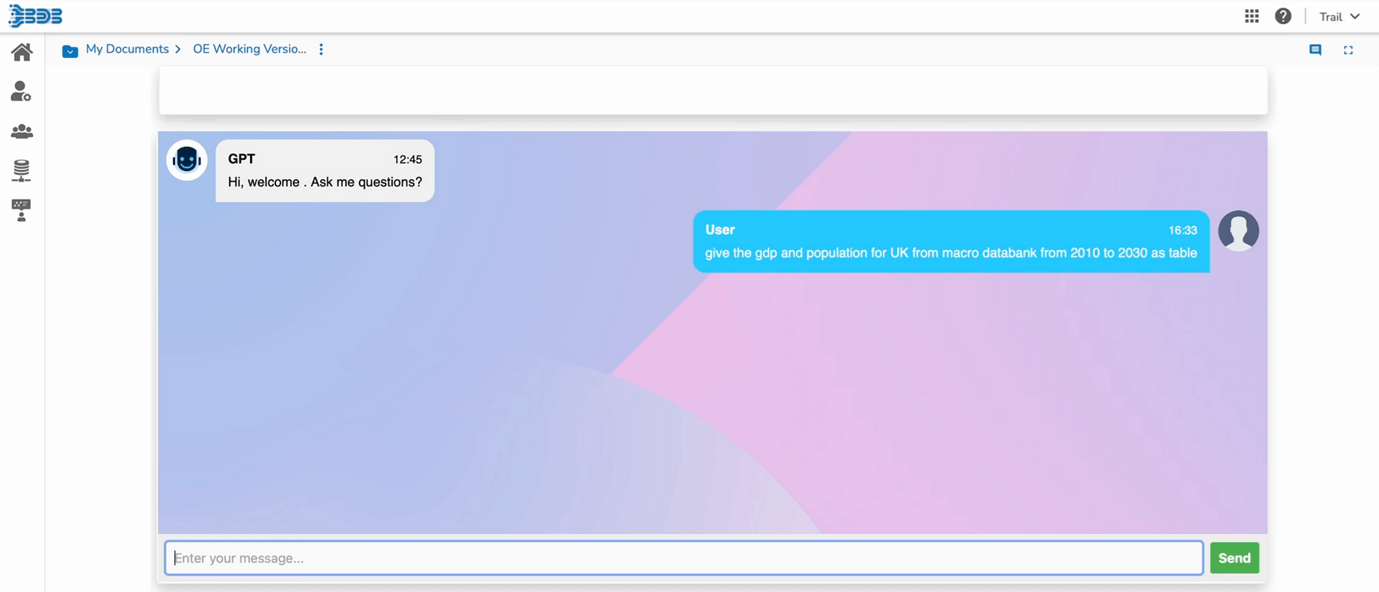
Input Prompt
When a user initiates a search or query, BDB platform utilises sophisticated algorithms to extract the most relevant documents from the Vector DB. This process involves comparing the embeddings of the user’s query with the embeddings of documents stored in the Vector DB. Documents with embeddings closely matching the query are identified and selected for further processing.
Step 3: Utilising Assist for Answer Generation
LLM Flow
With the relevant documents at hand, BDB leverages Assist, an advanced AI-powered tool, to generate precise answers based on the provided context. BDB Assist utilises state-of-the-art LLM, understanding the nuances of the user’s query and the context provided by the selected documents. This ensures that the generated answers are not only accurate but also contextually appropriate
Step 4: Returning Answers with Reference Documents/Data
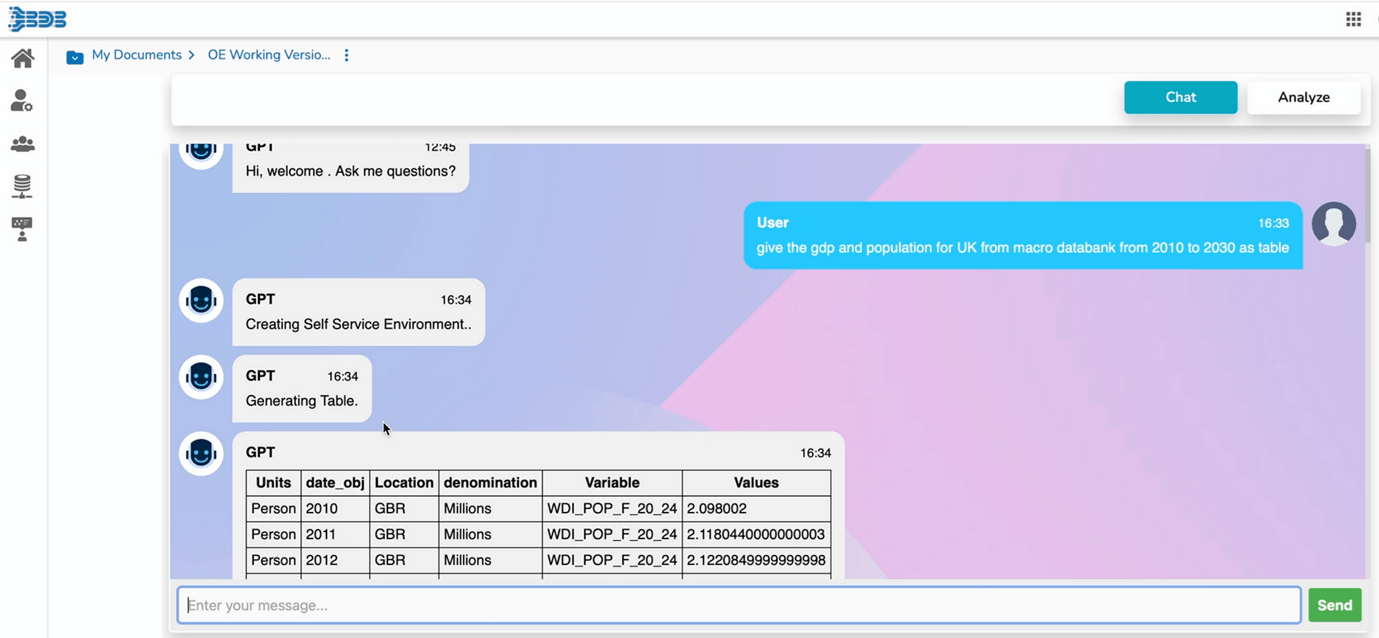
Getting Structured Data from Knowledge Base
The final step in the process involves presenting the generated response to the user along with the reference documents or relevant data .
This transparency is crucial, as it allows users to validate the authenticity of the information and delve deeper into the source material if necessary. By providing reference documents, BDB enhances the credibility of the answers and empowers users with the ability to explore the source contextually.
Conclusion
Retrieval augment generation, facilitated by the BDB platform, represents a paradigm shift in information retrieval methodologies. By combining the power of Open Source embeddings, LLMs and a robust Vector data base, BDB ensures that users receive highly relevant and accurate answers to their queries. This innovative approach not only saves time but also enhances the overall user experience by providing valuable context through reference documents.
In an era where information is abundant yet often overwhelming, BDB’s retrieval augment generation stands as a beacon of efficiency, guiding users towards meaningful and actionable insights. Embracing this technology can revolutionise the way businesses make decisions and access docs/data very easily.
References:
BDB Assist
Supported Vector DBs