Most Enterprise AI Agents Fail in Production. Here Is Precisely Why — and What Reliable Ones Are Actually Built On.
>50%
Enterprise AI Agent Pilot Failure Rate
— MIT State of AI in Business
Not because the AI is bad. Because the foundation underneath it is.
I want to be direct about something the industry is still dancing around: the AI agent is not the product. The foundation the agent operates on is the product. We figured this out twelve years ago — not because we were prescient, but because we were building a platform for production environments where getting it wrong has real consequences.
Our Data Pipelines, Data Agents in telecom are processing 65,000 records per second right now. They do not hallucinate. They do not break when source schemas change. They close the loop into operational systems without a human in the relay chain. That is not a model achievement. That is an architecture achievement.
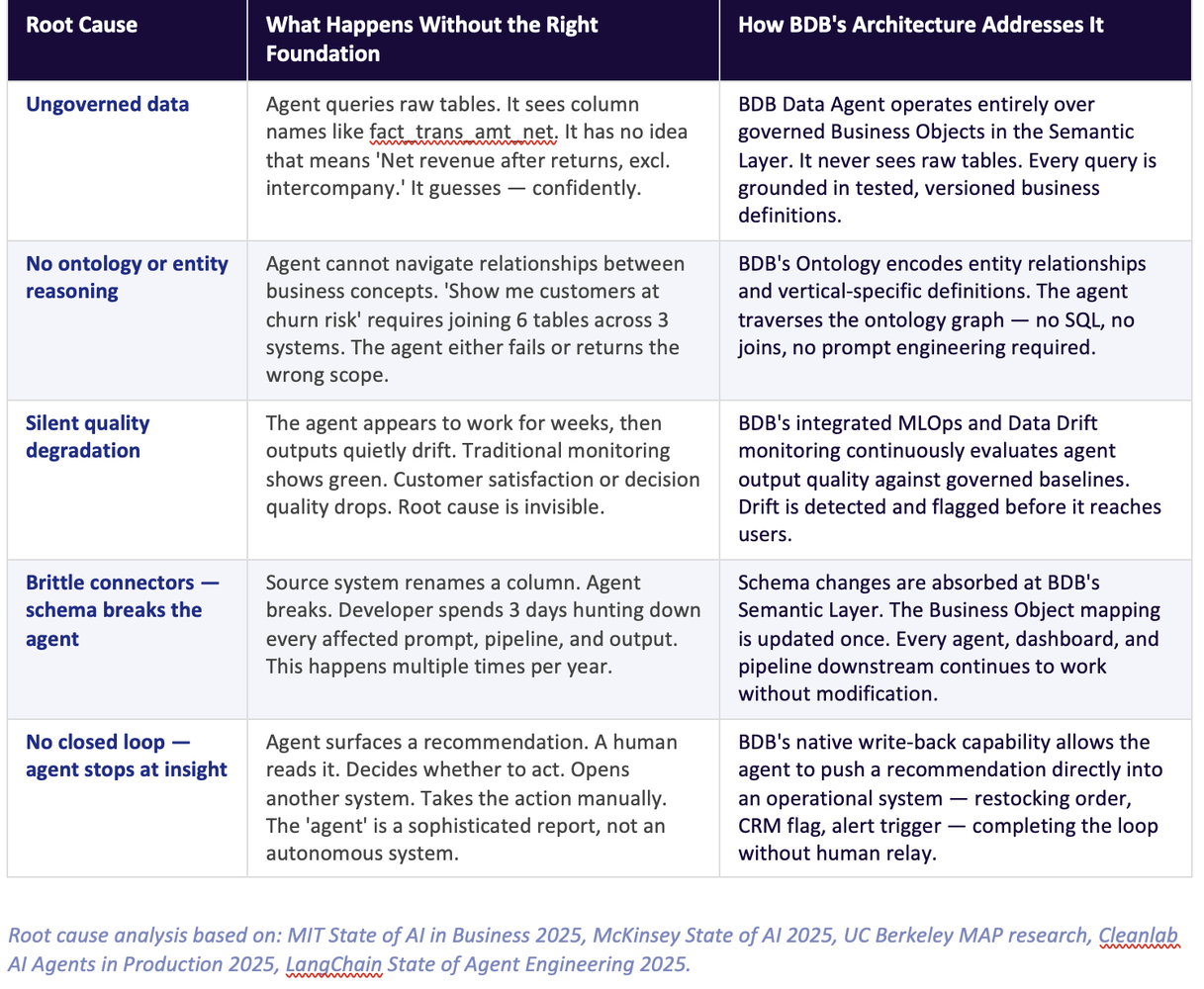
Why agents fail — the five root causes
The industry's post-mortems on failed AI agent deployments have converged on a consistent finding: the failure is almost never in the model. The failure is in the system the model was dropped into.
Research from MIT, McKinsey, UC Berkeley, and independent surveys of over 1,800 enterprise AI teams tells the same story: agents fail in production because they are operating on ungoverned, undocumented, semantically empty data. The LLM — however capable — cannot compensate for a foundation it cannot see or understand.
Here are the five specific failure modes, and how BDB's architecture addresses each:
Metadata first. Intelligence second. The companies that succeed with agentic AI understand this order of operations. The ones that fail deploy the intelligence first and then discover the metadata was always the missing piece.
The four-layer architecture that makes BDB agents reliable
BDB Data Agents — integrated natively with Claude — operate within a four-layer architecture where each layer has precisely defined access boundaries. The agent is powerful because it is constrained: it reasons over governed business context, not raw data. That constraint is not a limitation. It is the source of its reliability.
The practical consequence of this architecture is that a BDB Data Agent can be given to a business user — a regional sales manager, a CX lead, a supply chain analyst — without a data engineer in the loop for every query. The agent cannot produce a semantically incorrect answer because it has no access to semantically ambiguous data.
This is why our K-12 education deployment operates without hallucination. The agent accesses governed curriculum performance metrics, attendance definitions, and learning outcome Business Objects — all defined, tested, and version-controlled. There is no path from the agent to a raw table where ambiguity lives.
What reliable agents look like in production — by vertical
Telecom — Multi Country Deployment, 65,000 records per second (Peak Load)
Data Agents monitoring network and customer behaviour KPIs in real time. The agent does not query raw CDRs or network telemetry directly. It queries governed Business Objects — 'Churn Risk Score,' 'Network SLA Breach,' 'ARPU by Segment' — each defined in the Semantic Layer with the precise business logic telecom analysts have validated over years.
When the agent detects an anomaly — a sudden drop in ARPU in a region that correlates with a network SLA event — it traverses the Ontology to understand whether the pattern matches a churn precursor. It surfaces a structured insight to the CX team and, where configured, writes a retention flag directly into the CRM. The loop is closed without human relay. The output is auditable, traceable to the governing business definition, and consistent across every run.
Retail and campaign management — large enterprise deployments
In retail, campaign agents operate over governed definitions of 'same-store sales growth,' 'basket size by segment,' and 'promotional uplift.' The agent monitors daily performance against semantic thresholds, detects underperformance before it becomes a trend, and surfaces a ranked list of recommended interventions — each grounded in the business definitions the merchandising team trusts.
Campaign agents go further: they monitor response rates against governed audience definitions, detect segment fatigue in real time, and recommend campaign adjustments. In large enterprise deployments, these agents run continuously across multiple markets, replacing what used to be a weekly analyst cycle with a continuous, governed, automated intelligence loop.
Education — K-12 with zero hallucination
The K-12 education deployment is the one I find most satisfying to describe, because education is a domain where trust in data is non-negotiable. A school administrator asking 'which students are at risk of falling behind in mathematics this term' cannot receive a plausible-sounding wrong answer. The consequences are real children.
Our K-12 agent operates over governed learning outcome definitions, attendance Business Objects, and assessment performance metrics — all defined in partnership with educational data teams who know exactly what 'at risk' means in their specific curriculum context. The agent has produced zero hallucinations in production because there is no semantic ambiguity in the layer it operates over. The foundation is the protection.
Healthcare — the honest timeline
I want to be transparent about healthcare, because honesty here is more useful than optimism.
Healthcare will be one of the highest-value verticals for agentic AI — patient pathway optimisation, clinical outcome monitoring, resource allocation, readmission risk. The use cases are clear. The ROI is enormous. But most healthcare organisations do not yet have the data management foundation that makes reliable agent deployment possible. Patient data is fragmented across systems, clinical definitions vary by department, and data quality is inconsistent at the source.
Deploying an AI agent into that environment today would reproduce the same failure modes that are killing enterprise AI pilots in every other sector — except in healthcare, the consequences of a confident wrong answer are clinical, not just financial.
Our view, based on current delivery experience: healthcare data management foundations will be built through 2025–27. The semantic layer and ontology layer will be added through 2026–28. Reliable agent deployment in healthcare production environments will begin to be viable from approximately 2028–29. That is not pessimism. It is the correct order of operations.
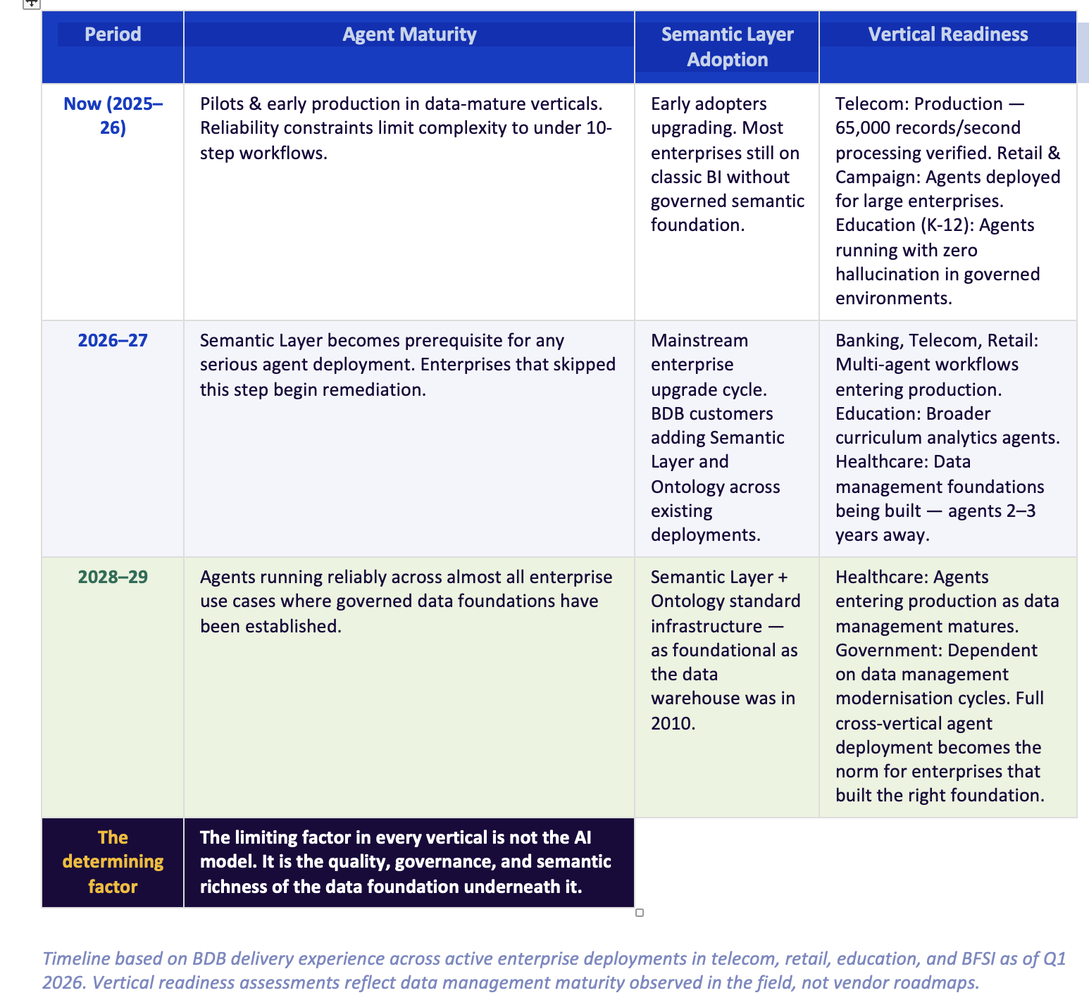
The industry timeline — an honest forecast
Based on what we are seeing across active deployments in telecom, retail, education, and BFSI, here is our current view of how the agentic AI production curve develops over the next four years:
The critical insight is this: the determining factor in every vertical, at every stage, is not the AI model. Databricks, Azure, AWS, and GCP all give you access to world-class LLMs. The question is never 'which model?' The question is always 'what is the model operating on?'
Companies that build the semantic foundation now — in 2026 and 2027 — will be the ones with reliable agents in production by 2028. Companies that deploy agents on ungoverned data today will be rebuilding their foundations in 2027, having spent two years and significant budget on pilots that never reached production trust.
The AI agent race is not being won in the model layer. It is being won — quietly, without conference keynotes — in the data foundation layer. The companies that understand this in 2026 will be three years ahead of the ones that discover it in 2029.
The architectural choice we made — and why it matters
We made a deliberate decision when we built BDB's Data Agent framework: we integrated Best Models (Claude, OpenAI, Qwen, Gemini etc.) — as our reasoning engine rather than attempting to build our own LLM. This was not a cost decision. It was a philosophy decision.
We spent twelve years building what takes twelve years to build correctly: the data foundation, the semantic layer, the ontology, the pipelines, the governed business context. We did not spend those years trying to replicate what Anthropic, OpenAI, and Google have already built at a quality level we cannot match. We built what they cannot match — the enterprise data platform that makes their models reliable in production.
- Integration over duplication. Foundation over feature race.
- BDB's Semantic Layer and Ontology are model-agnostic. As reasoning models improve, BDB deployments benefit automatically.
- A customer running BDB today is not locked into today's model capability. They are positioned to absorb every improvement in LLM reasoning over the next decade.
What to do right now if you are serious about agents in production
If you are a CDO or CTO planning your agentic AI roadmap, here is the sequence that the evidence — and our production experience — supports:
1
Audit your data foundation first.
Before evaluating any agent platform, assess whether your core business metrics have a single, governed, tested definition that every tool in your stack agrees on. If they do not, your first investment is in the Semantic Layer — not the agent.
2
Build the ontology for your most important domain.
Start with the one vertical or business unit where agent ROI is highest. Map the entity relationships. Define the business concepts in machine-readable form. This takes months, not years — especially with a platform like BDB where the ontology tooling is native.
3
Deploy one agent that closes a loop.
Not a chatbot. Not a dashboard assistant. An agent that detects a condition, reasons about it, surfaces an insight, and takes an action in an operational system. Prove the loop works in one domain before expanding.
4
Measure reliability, not just output.
Define what 'correct' looks like for your agent before you deploy it. Build evaluation into the workflow from day one. An agent that is 80% correct in a demo and 60% correct in production six months later has not been monitored — it has been trusted.
We are working with enterprises in telecom, retail, education, and BFSI across this exact sequence right now. The results in verticals where the data foundation is strong are production-grade and measurable. The results in verticals where foundations are weak are consistent with the high failure rate in the research.
The foundation is not a prerequisite to the agent. The foundation is the agent.
Next — and final — in this series: Article 6 is the one I have been building toward. Not a product article. A perspective on where enterprise data and AI is going, what it takes to build the platforms that get us there, and what the global market is missing by not looking at what has been quietly built in India over the last twelve years.
Most Enterprise AI Agents Fail in Production. Here Is Precisely Why.